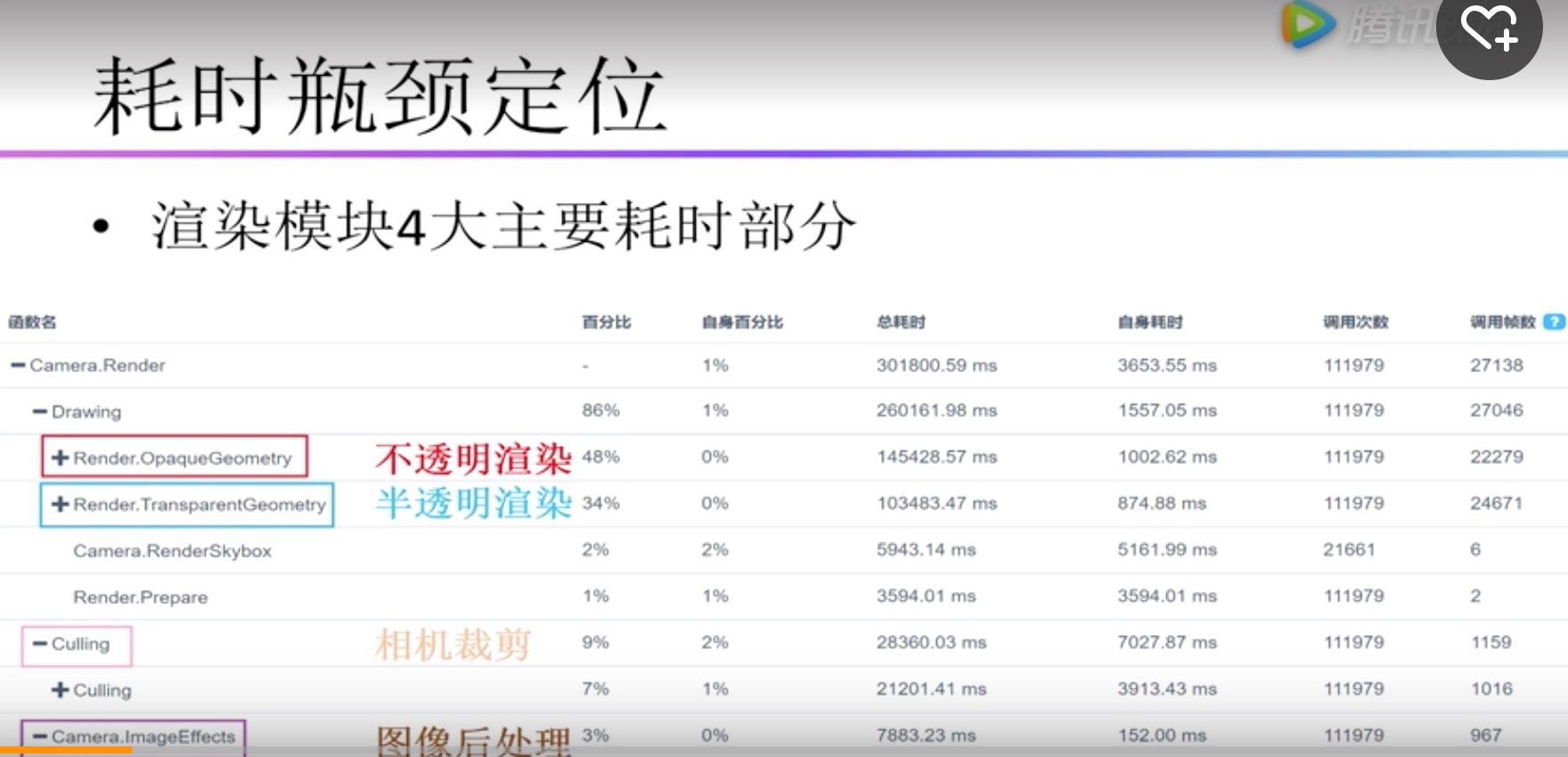
| Camera.Render | 渲染模块 |
|---|---|
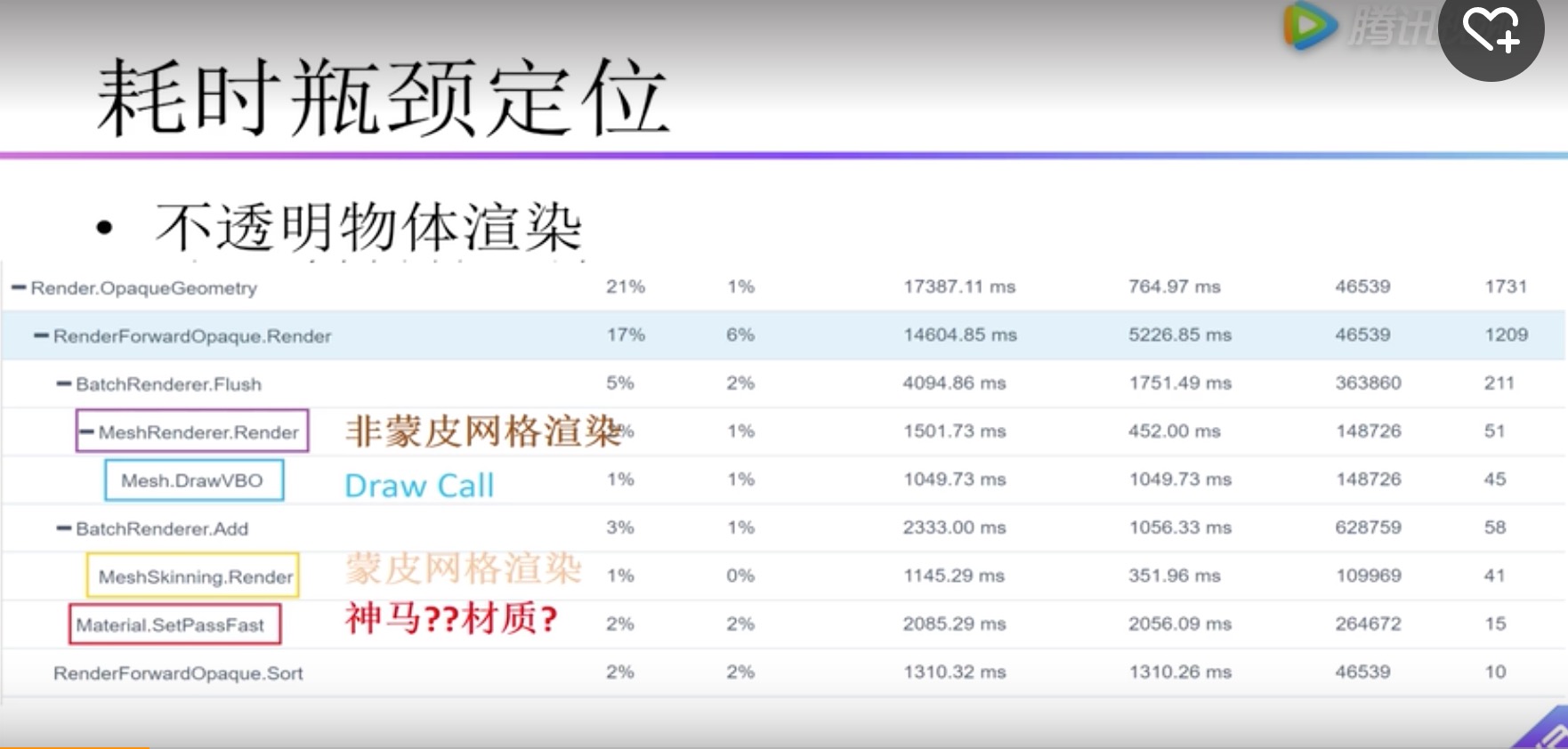
| Render.OpaqueGeometry | 不透明渲染 |
| MeshRenderer.Render | 非蒙皮网格渲染 |
| Mesh.DrawVBO | Draw Call |
| MeshShinning.Render | 蒙皮网格渲染 |
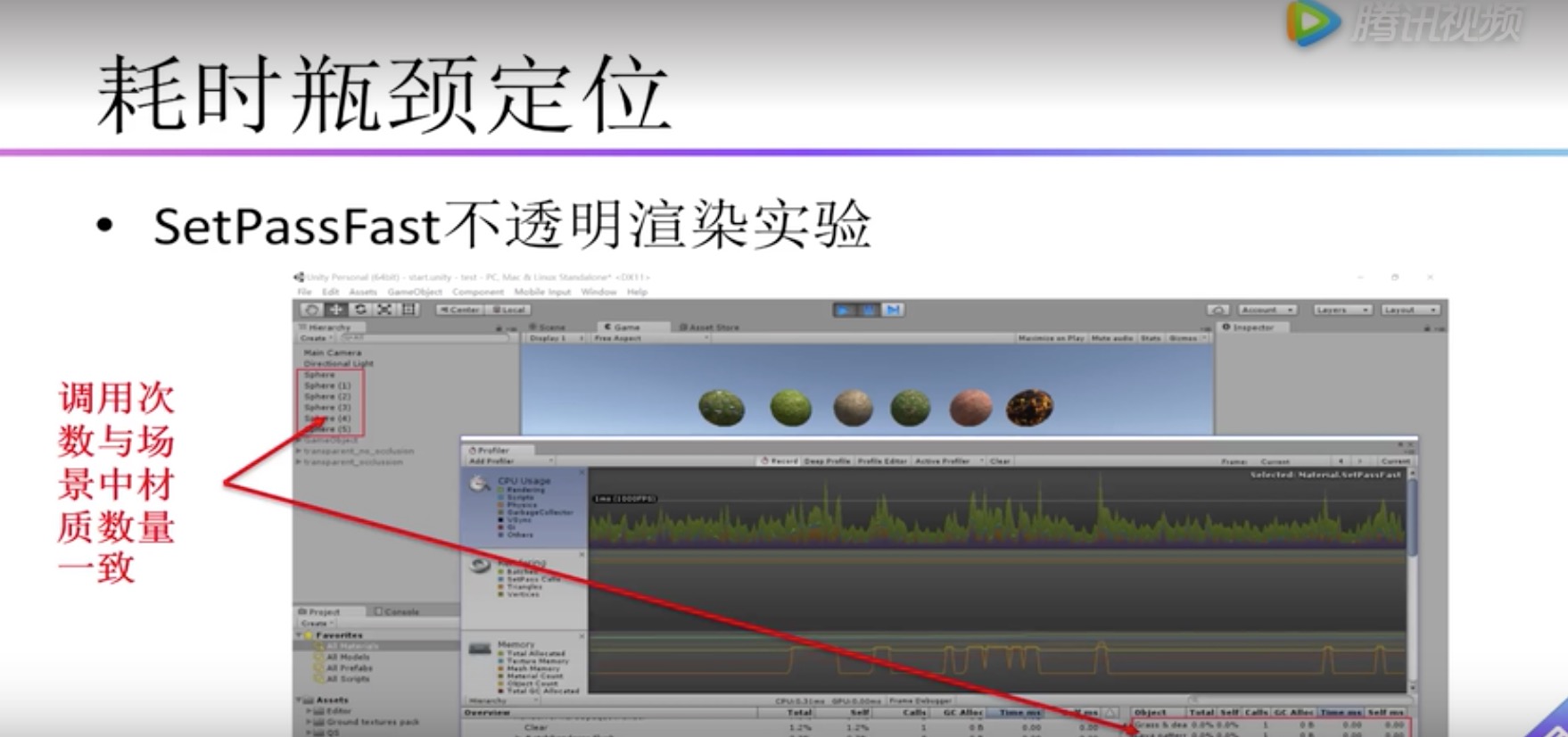
| Material.SetPassFast | 场景中不同材质数量造成;和DrawCall类似,如果两个相同材质物体中间有一个其他材质的物体,就无法合批,这个材质就会成2个SetPassFast |
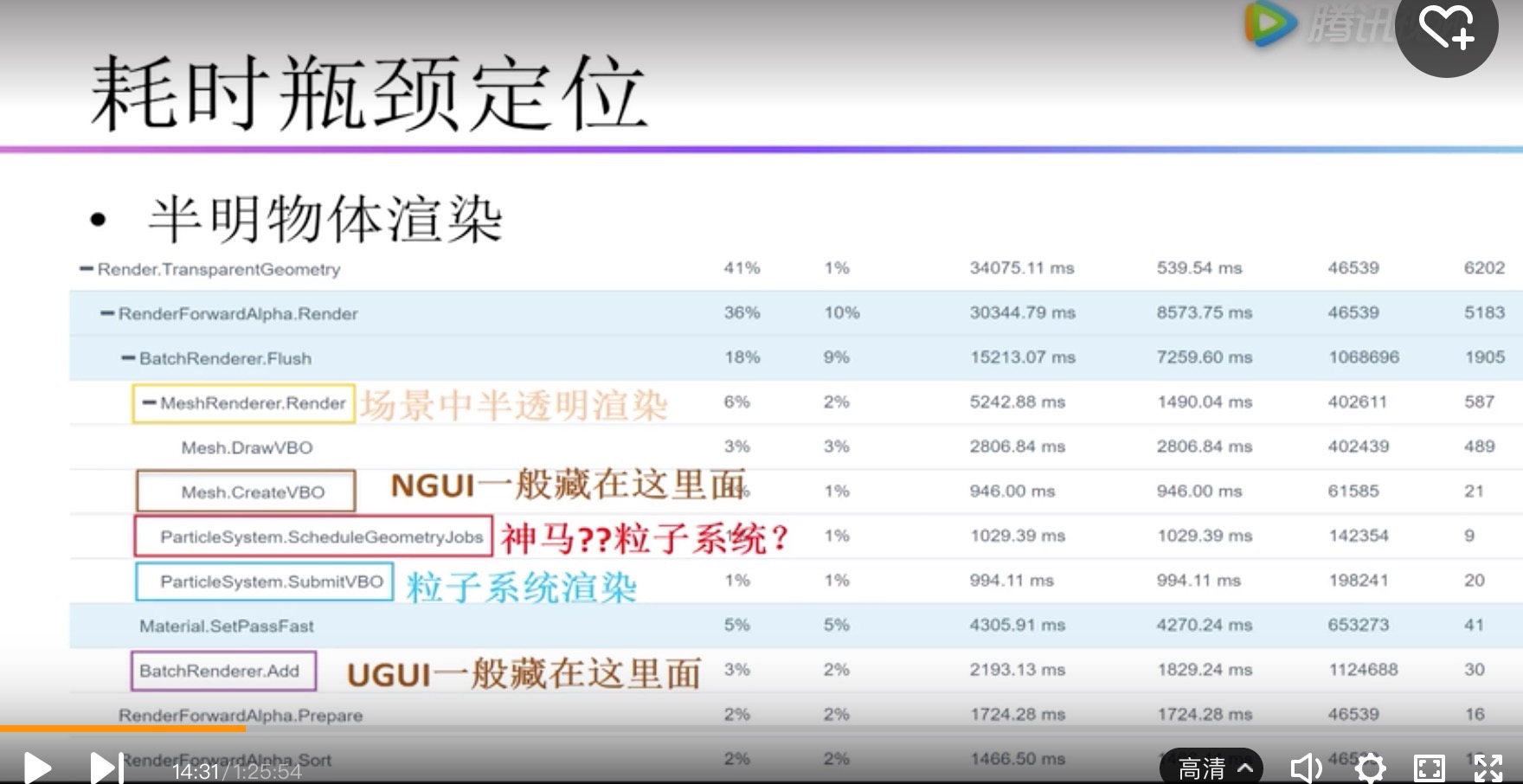
| Render.TransparentGeometry | 半透明渲染 |
| Mesh.DrawVBO | NGUI 一般藏在这里面 |
| ParticleSystem.ScheduleGeometryJobs | 粒子系统 |
| ParticleSystem.SubmitVBO | 粒子系统渲染,提交粒子系统VBO的操作 |
| BatchRenderer.Add | UGUI一般藏在这里面, Canvas绑定了Camera的会显示在这里面。没有绑定Camera的Canvas不会显示在这里(Camera.Render) |
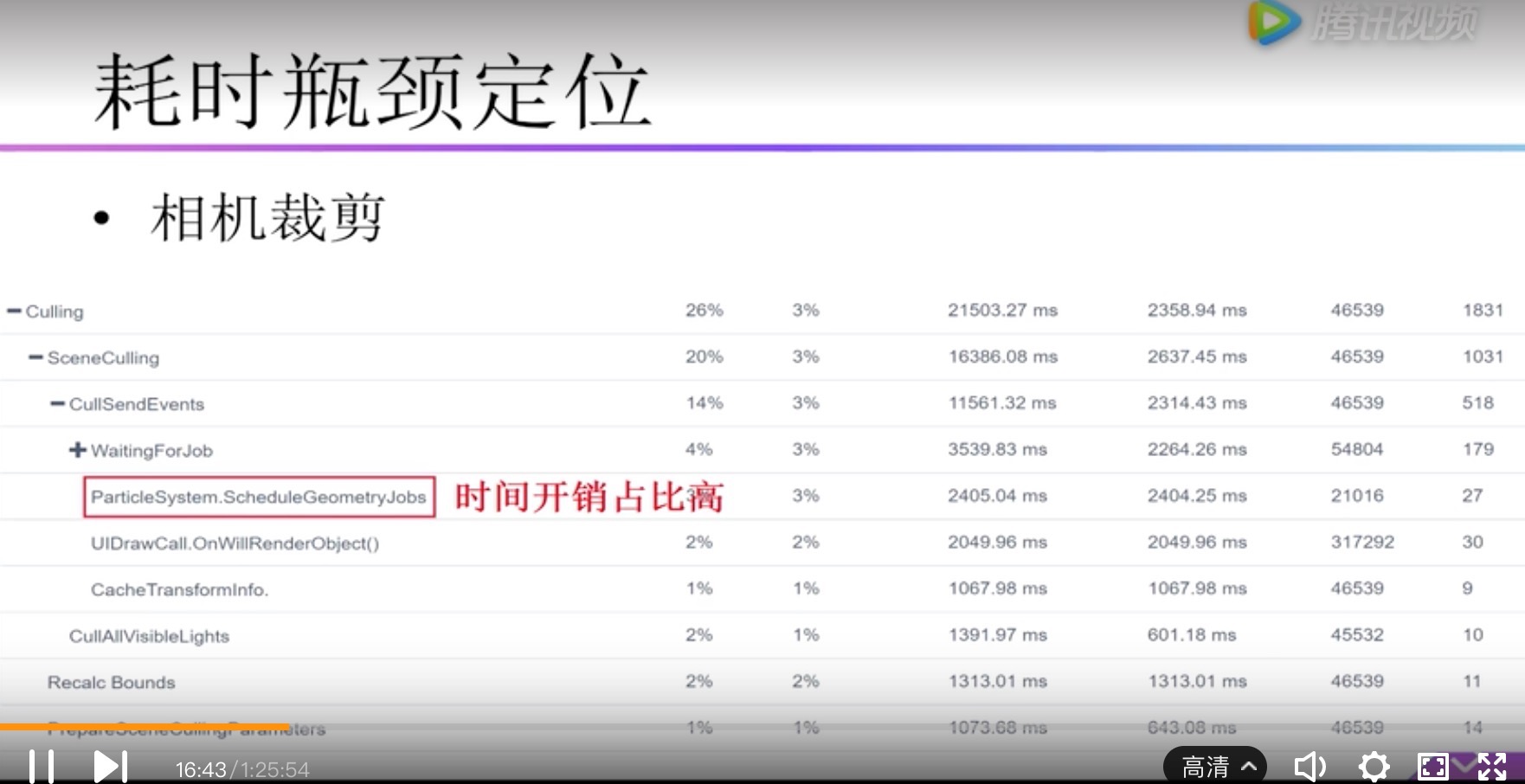
| Culing | 相机裁剪 |
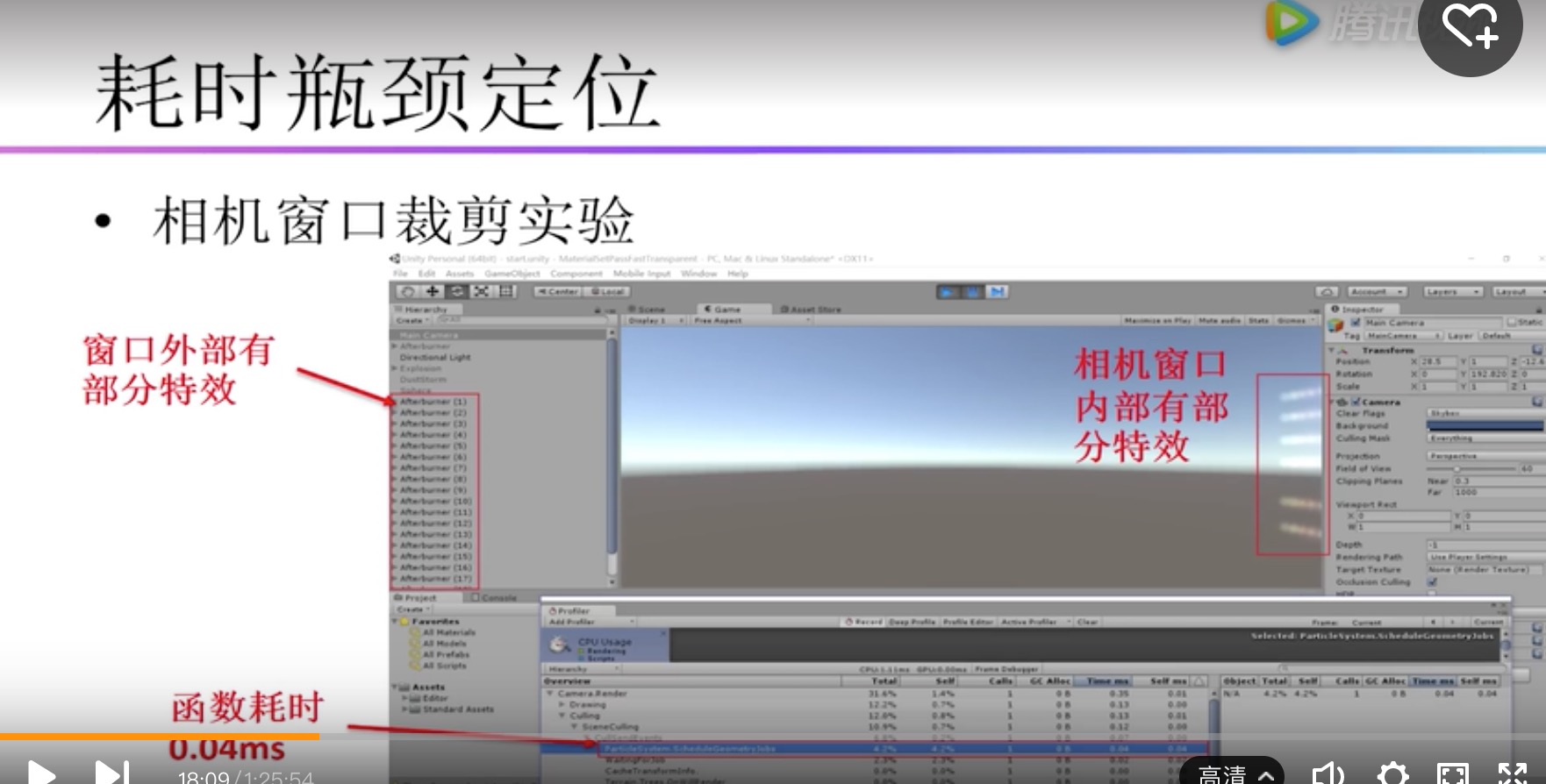
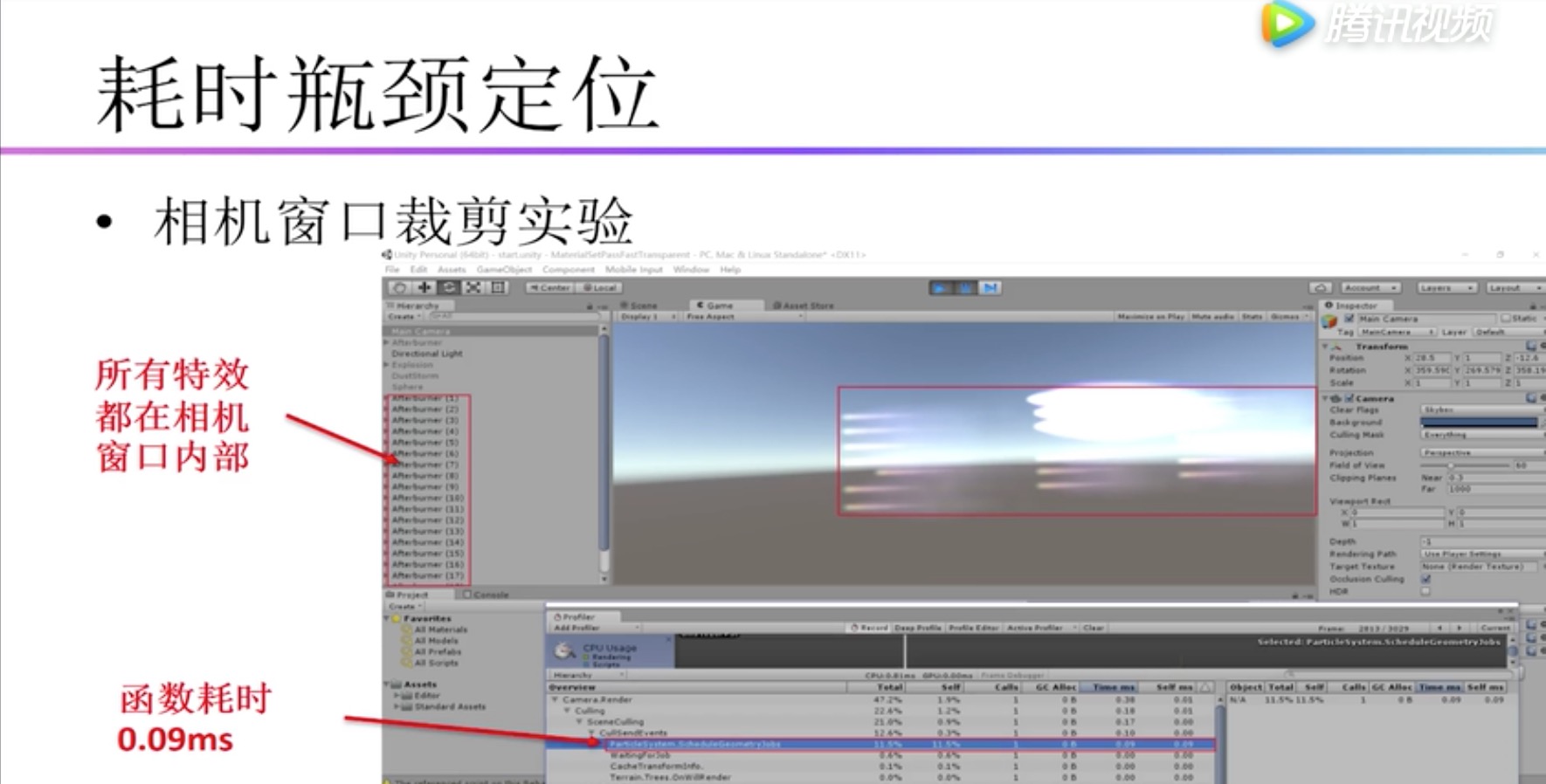
| ParticleSystem.ScheduleGeometryJobs |
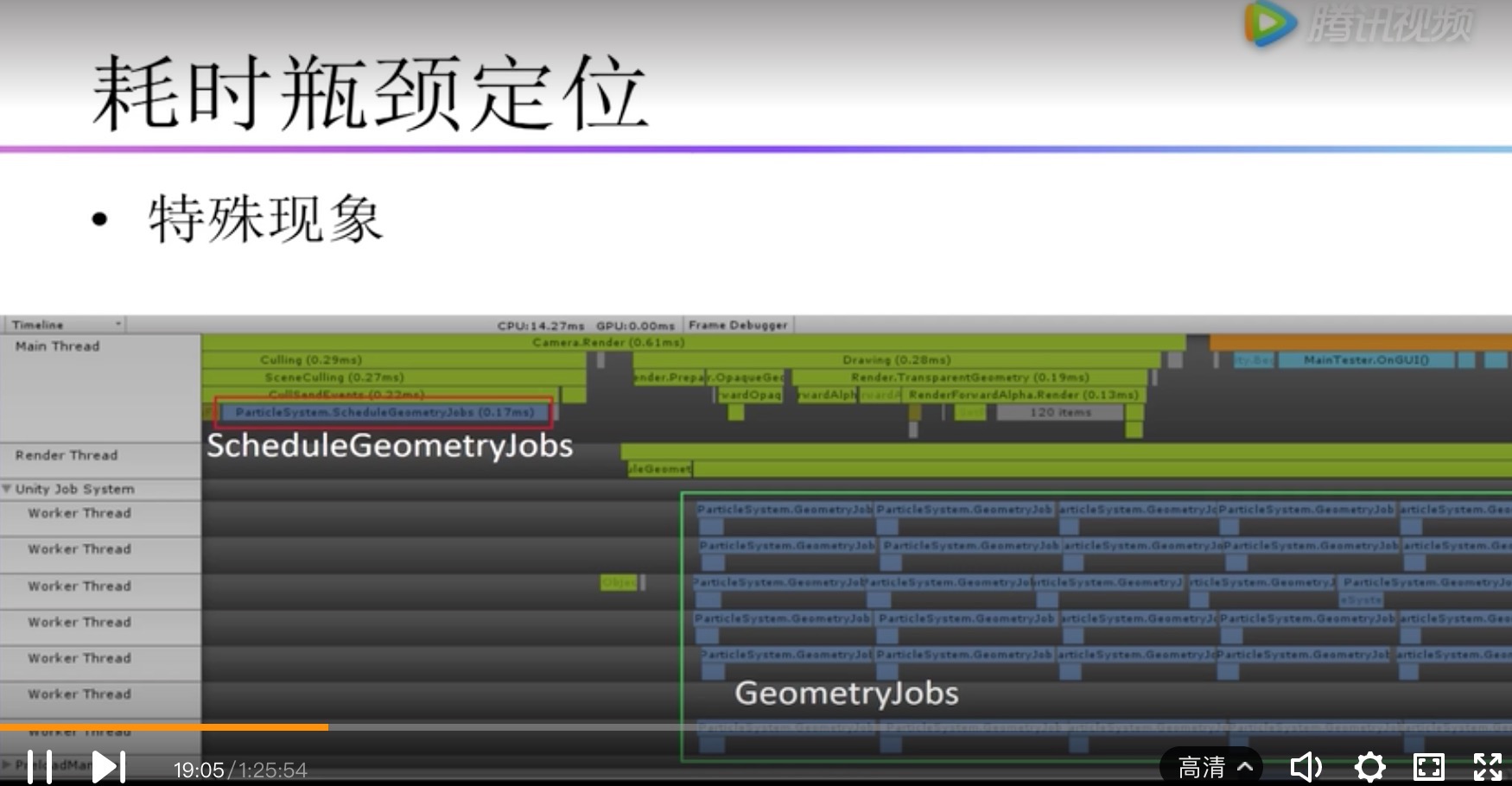
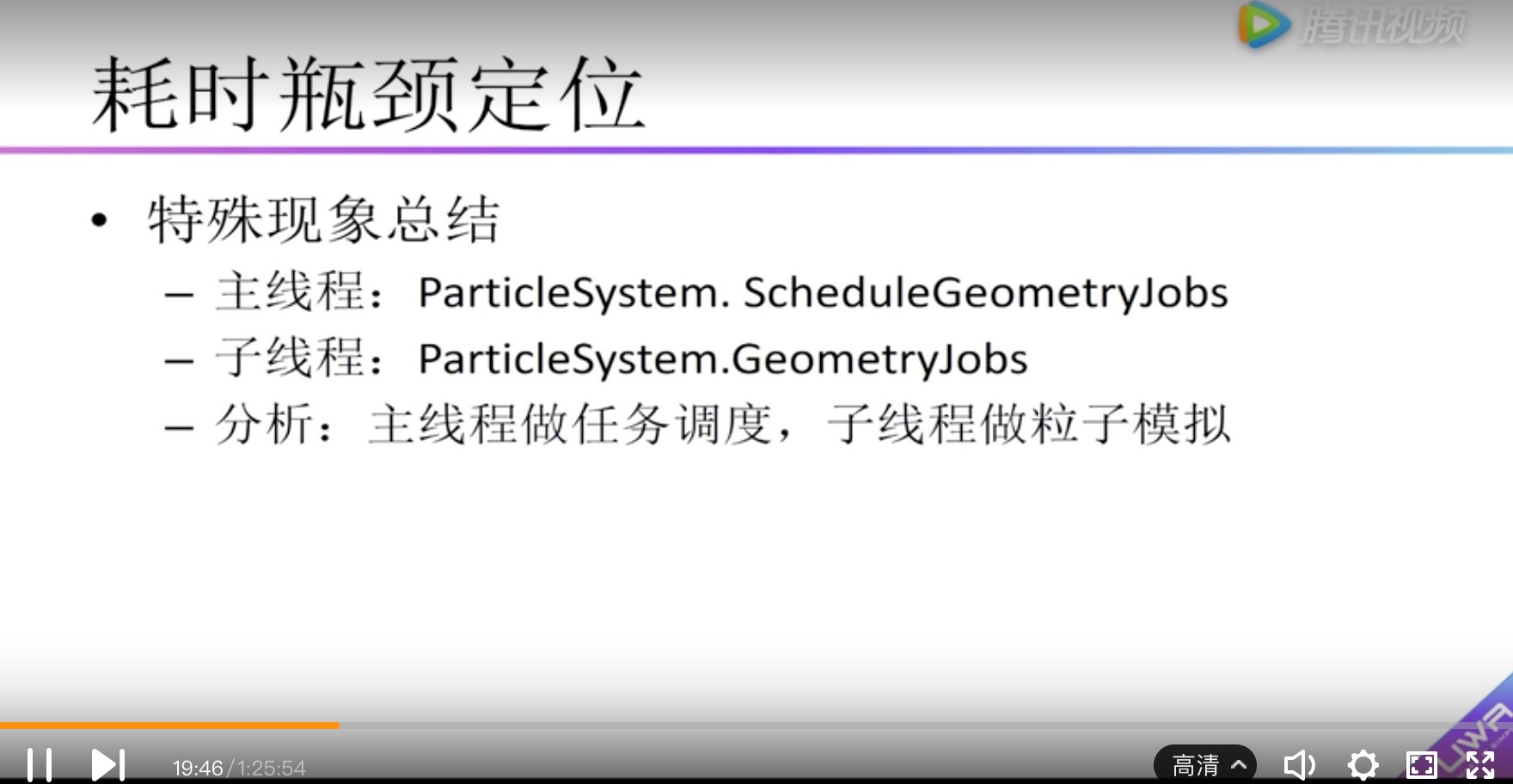
这个函数不仅出现在Render.TransparentGeometry,也会出现在Culing里。通常他的时间占比比较高(2%-3%左右)。 如果粒子系统没有在摄像视窗内就不会有;如果在摄像机视窗内部的粒子系统越多,消耗越大。所以与摄像机视窗内粒子系统个数成正比。 主线程:ParticleSystem.ScheduleGeometryJobs 子线程:ParticleSystem.GeometryJobs 分析: 主线程做任务调度,子线程做粒子模拟 |
| Camera.ImageEffects | 图形后期处理 |
渲染模块
渲染模块/不透明渲染
Material.SetPassFast
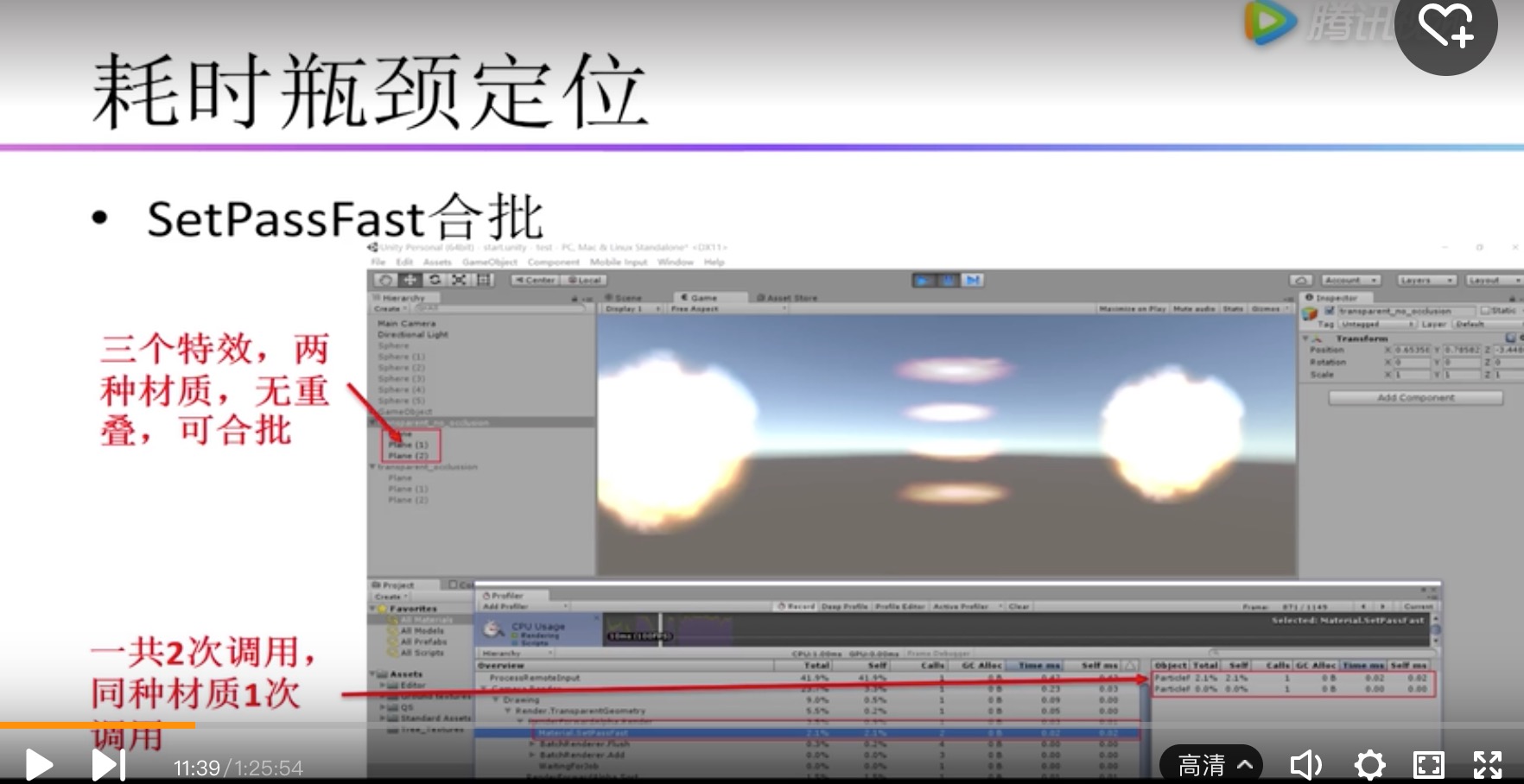
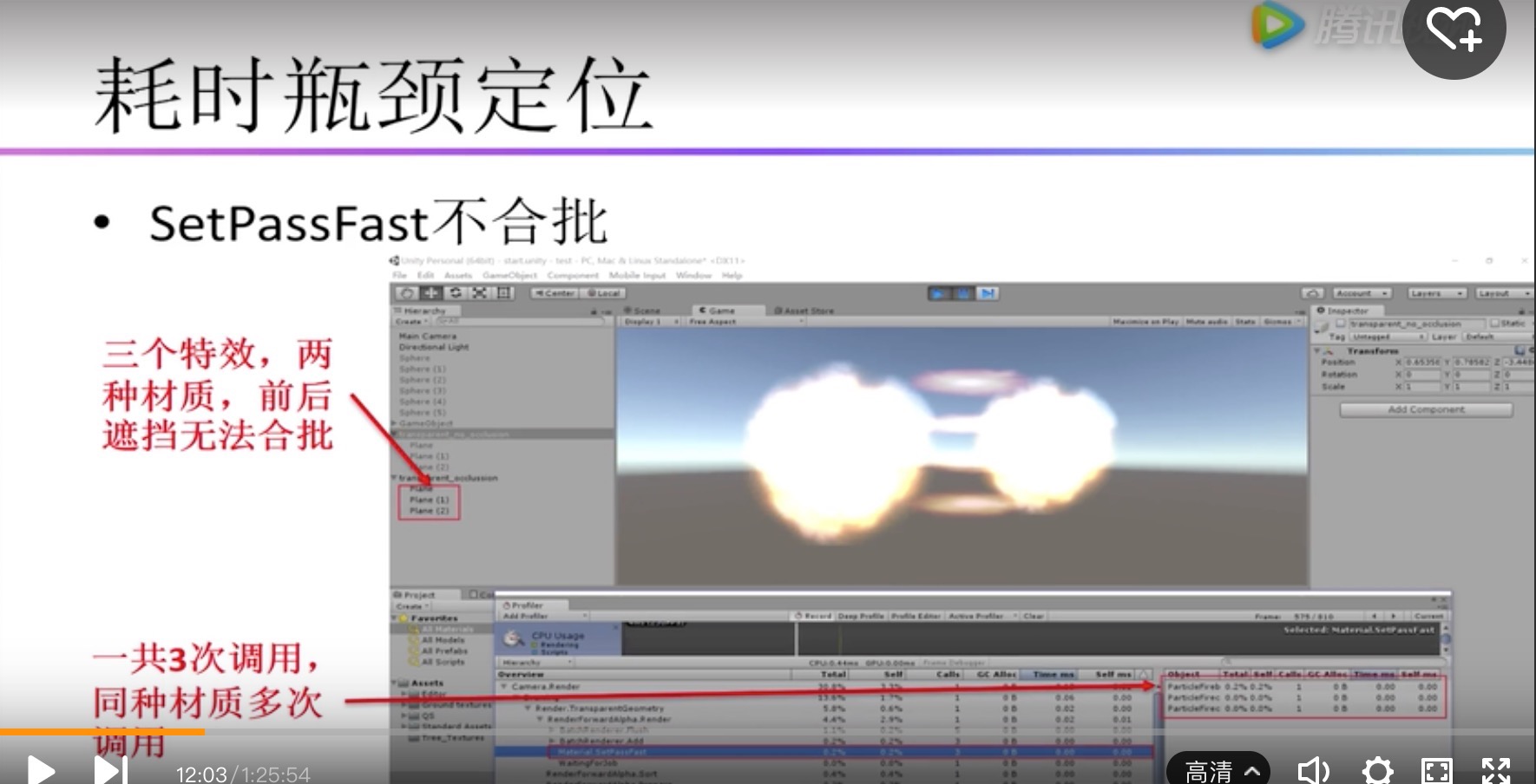

Render State包含深度测试、半透明渲染、Blend混合、材质Texture修改和绑定.
所以优化不仅要控制DrawCall,还有控制Material的数量,不能太多。
渲染模块/半透明渲染
渲染模块/相机裁剪
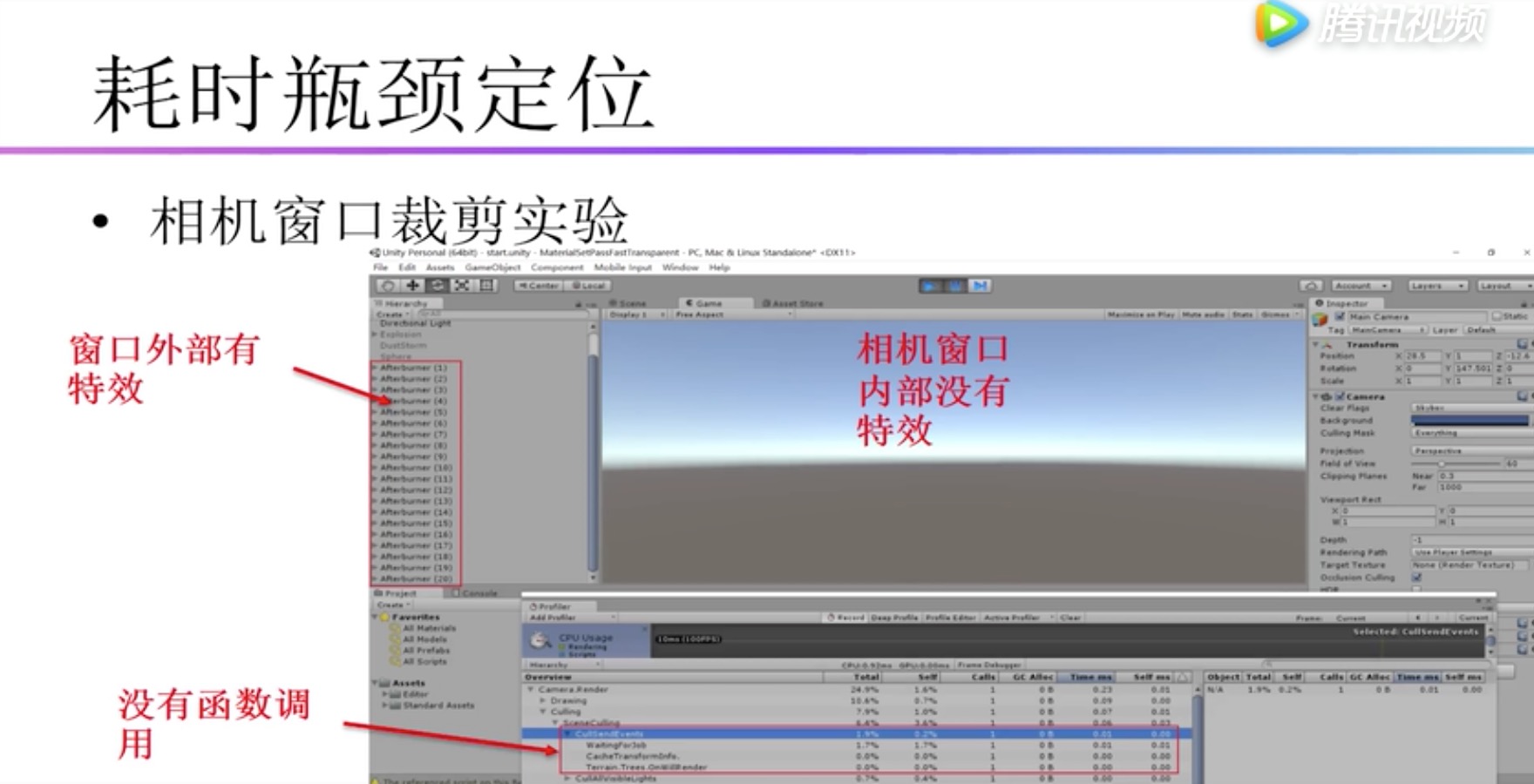
ParticleSystem.ScheduleGeometryJobs

渲染模块,如何优化?
根据上面提到的查看profiler,定位问题出在哪个定方。然后去对美术效果做删减,让美术效果和运行效率做一个平衡。
问题方向






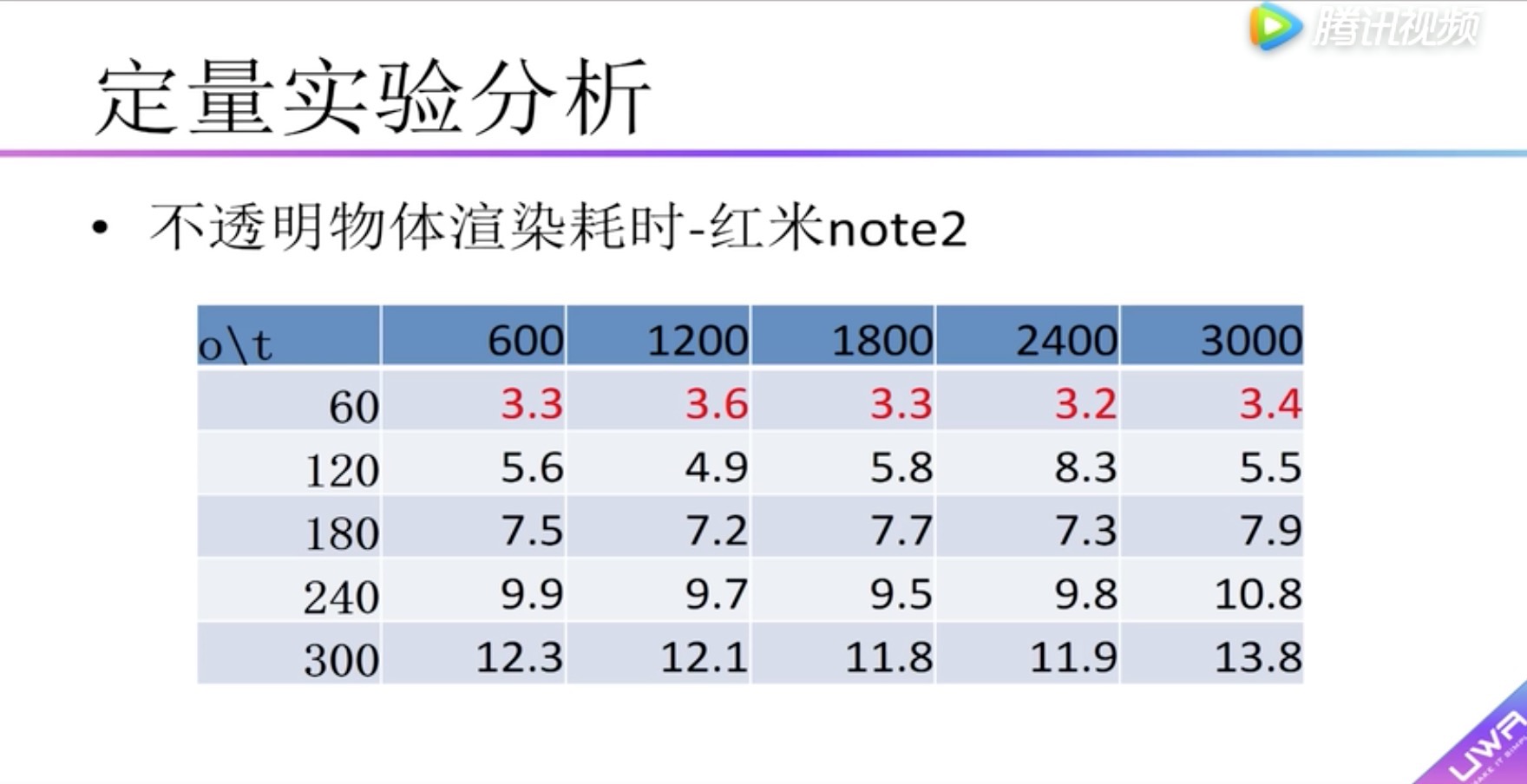
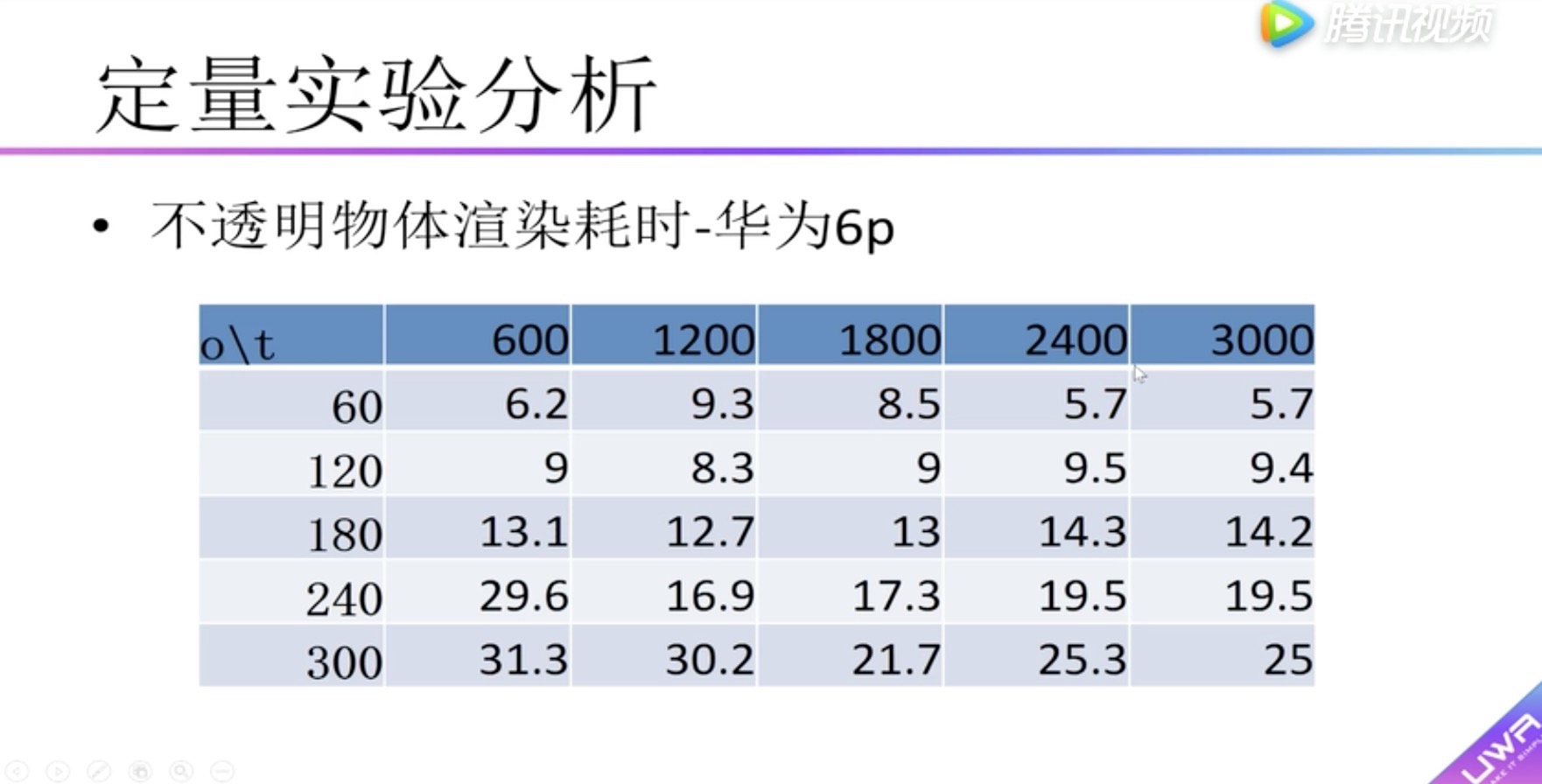
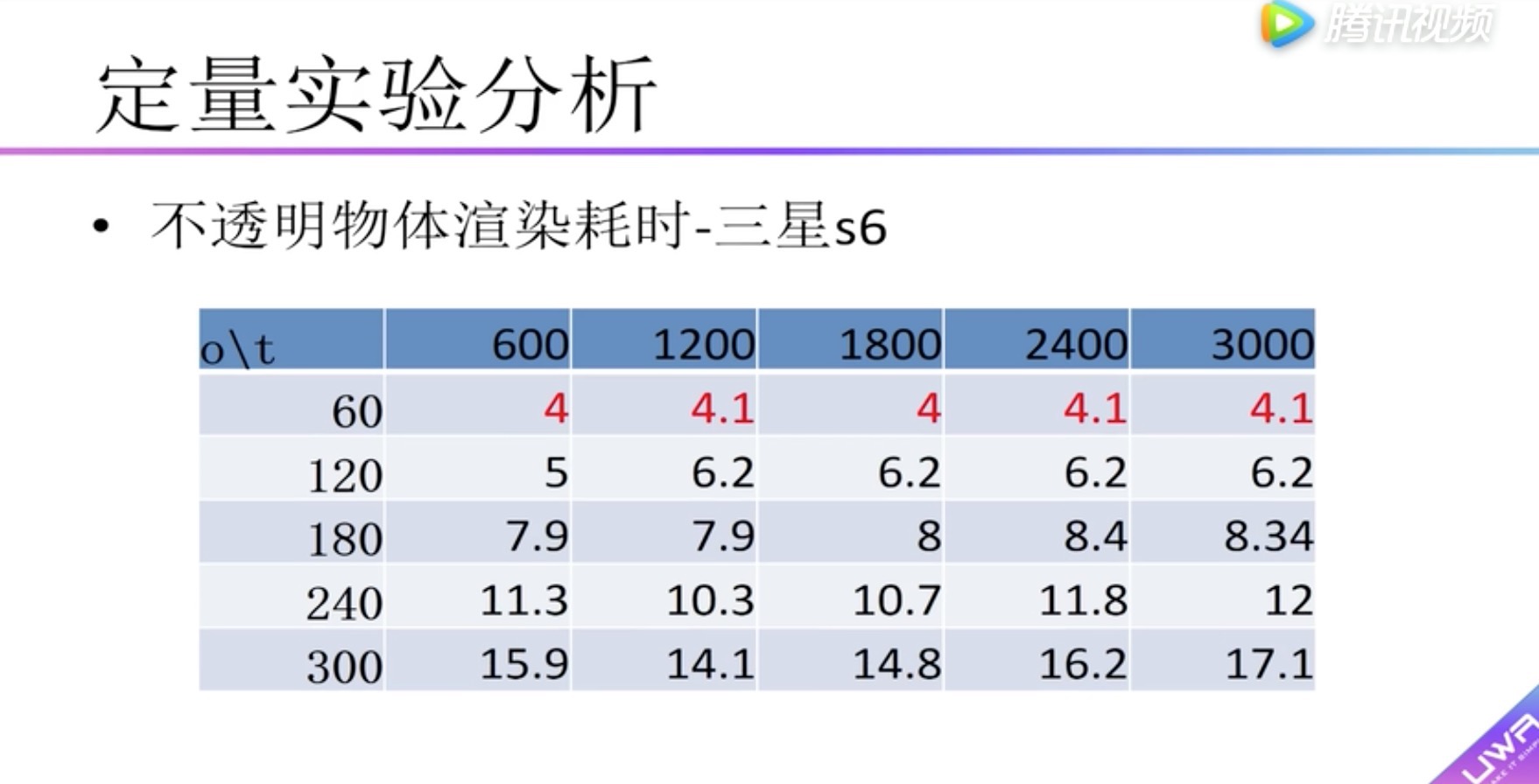
定量实验分析 不透明物体渲染性能实验

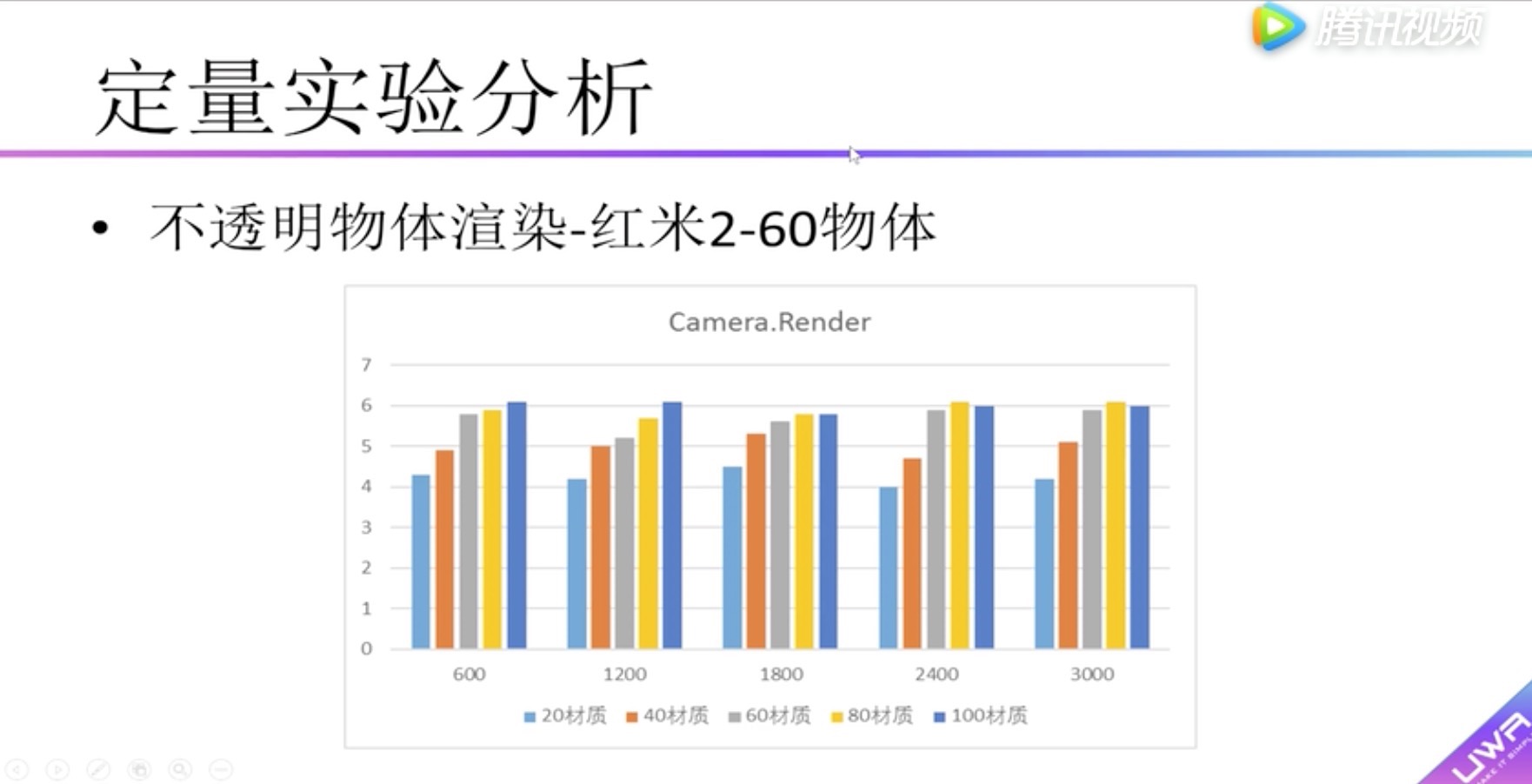
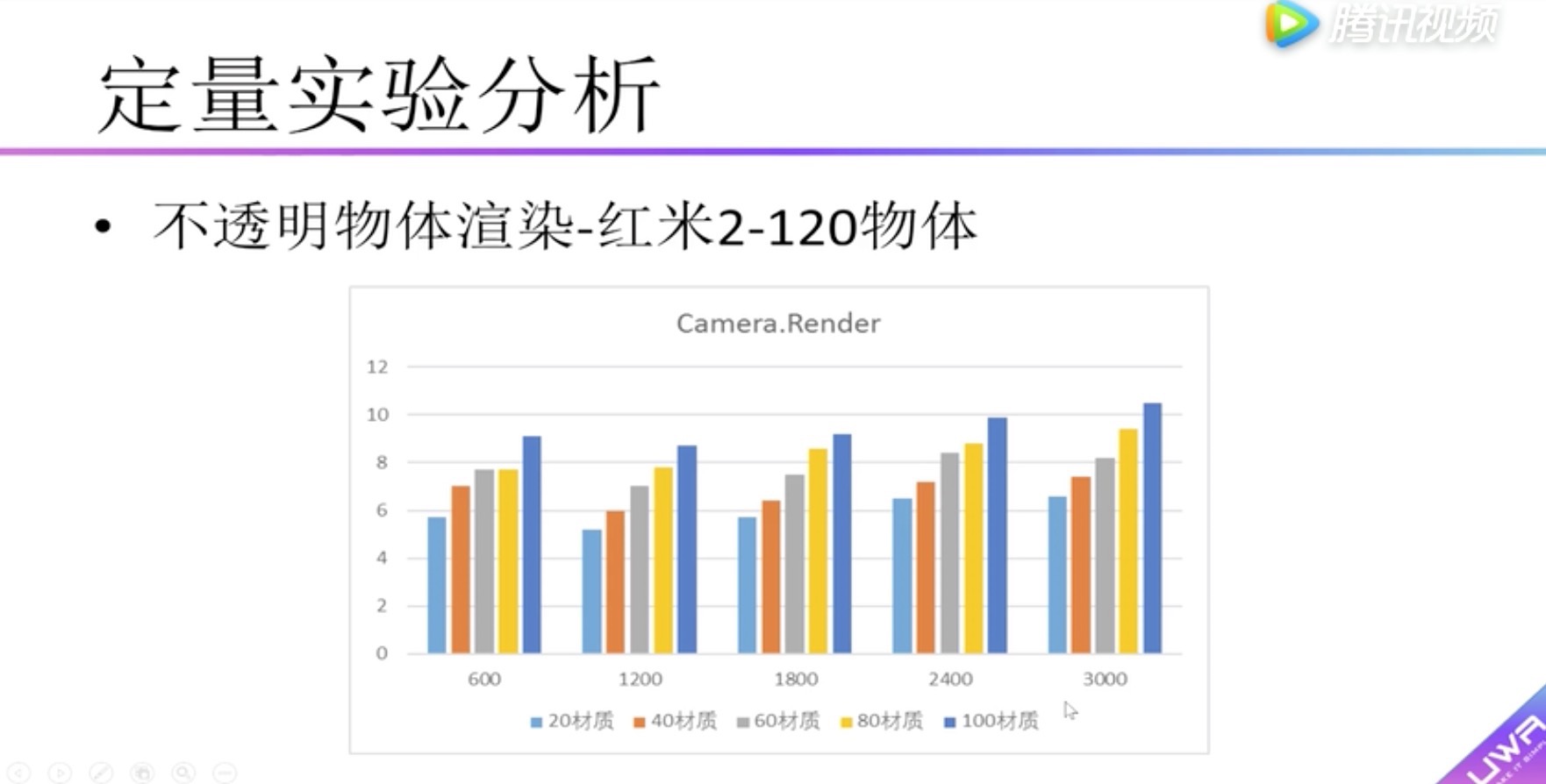
纵坐标:渲染耗时 单位毫秒。
横坐标:物体面片数。
柱状图:不同颜色材质数量
发现1:随着材质数的增加,渲染耗时也增加;物体面片数的增加,渲染耗时并不那么明显。
发现2:60个物体图和120个物体图对比,可以发现因为Draw Call数量的增加,对渲染耗时有比较大的影响。


为什么小于5毫秒呢?
因为游戏一般以30帧为界限。
假如游戏设定帧频为30帧,那么每帧的时间是33毫秒。
在这33毫秒中分配给渲染大概是15毫秒。
在这15毫秒中要做:不透明物体渲染、半透明物体渲染、阴影、粒子系统、图像后处理等。
所以分配给不透明物体渲染的时间大概在3-5毫秒。
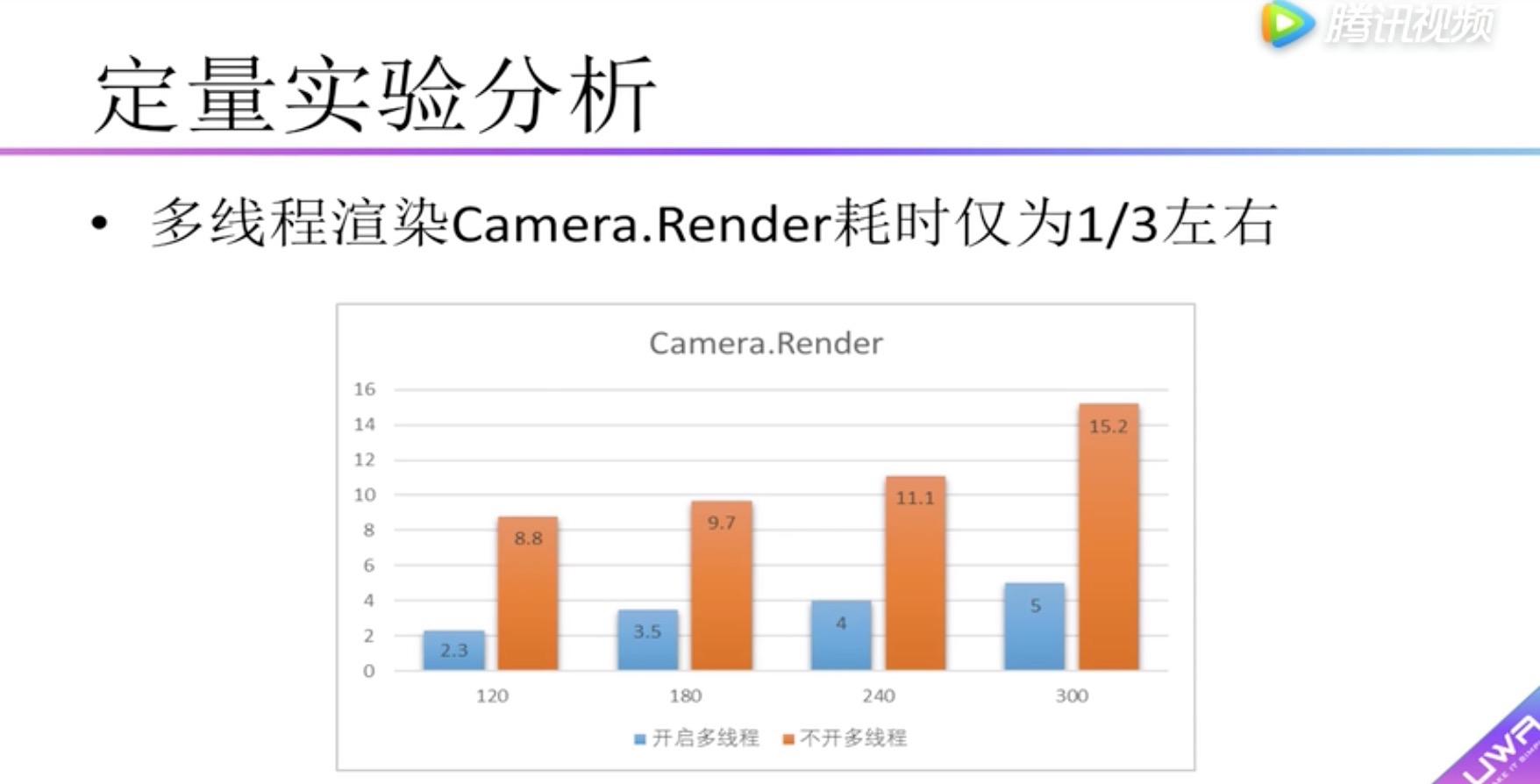
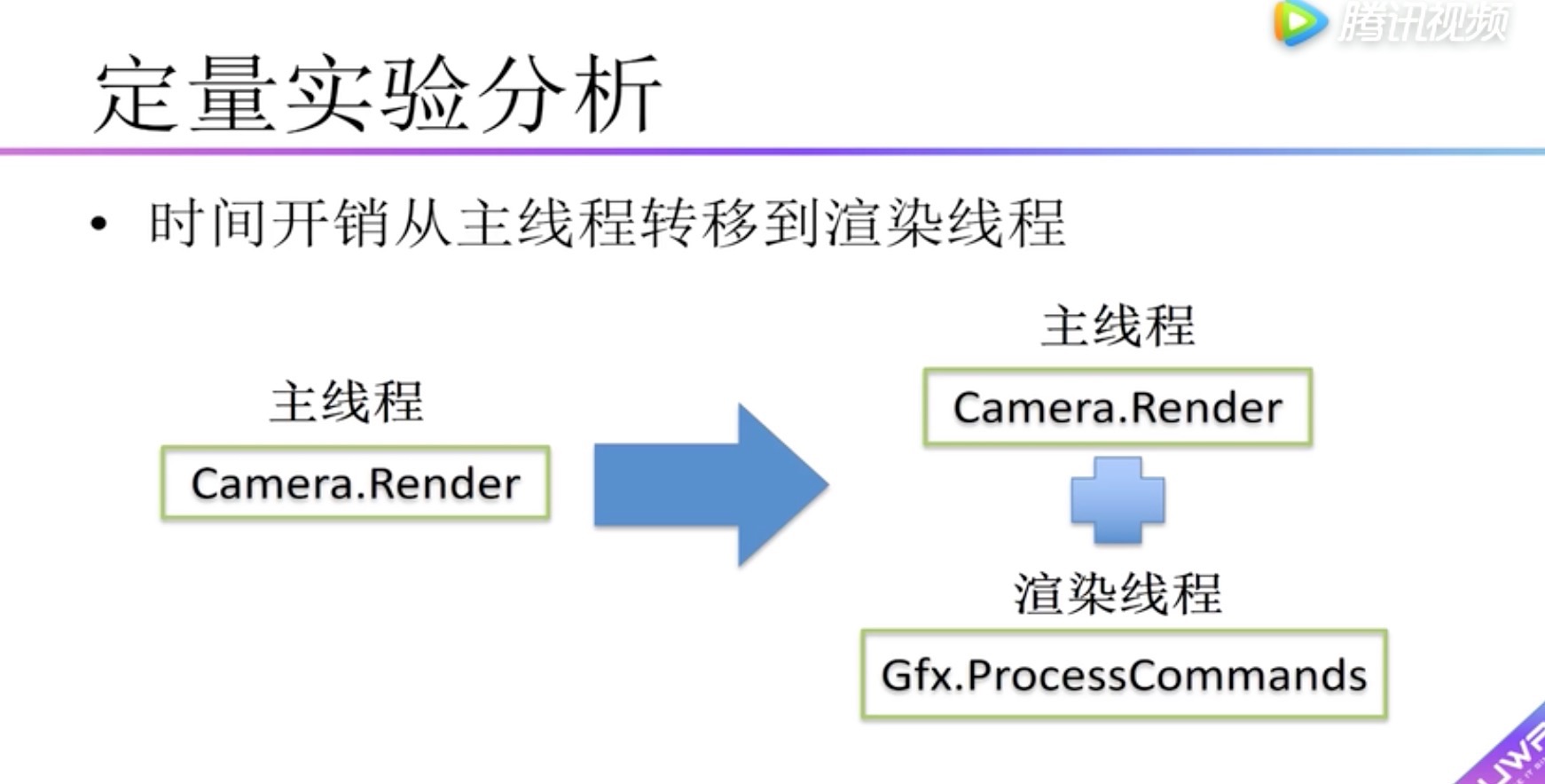
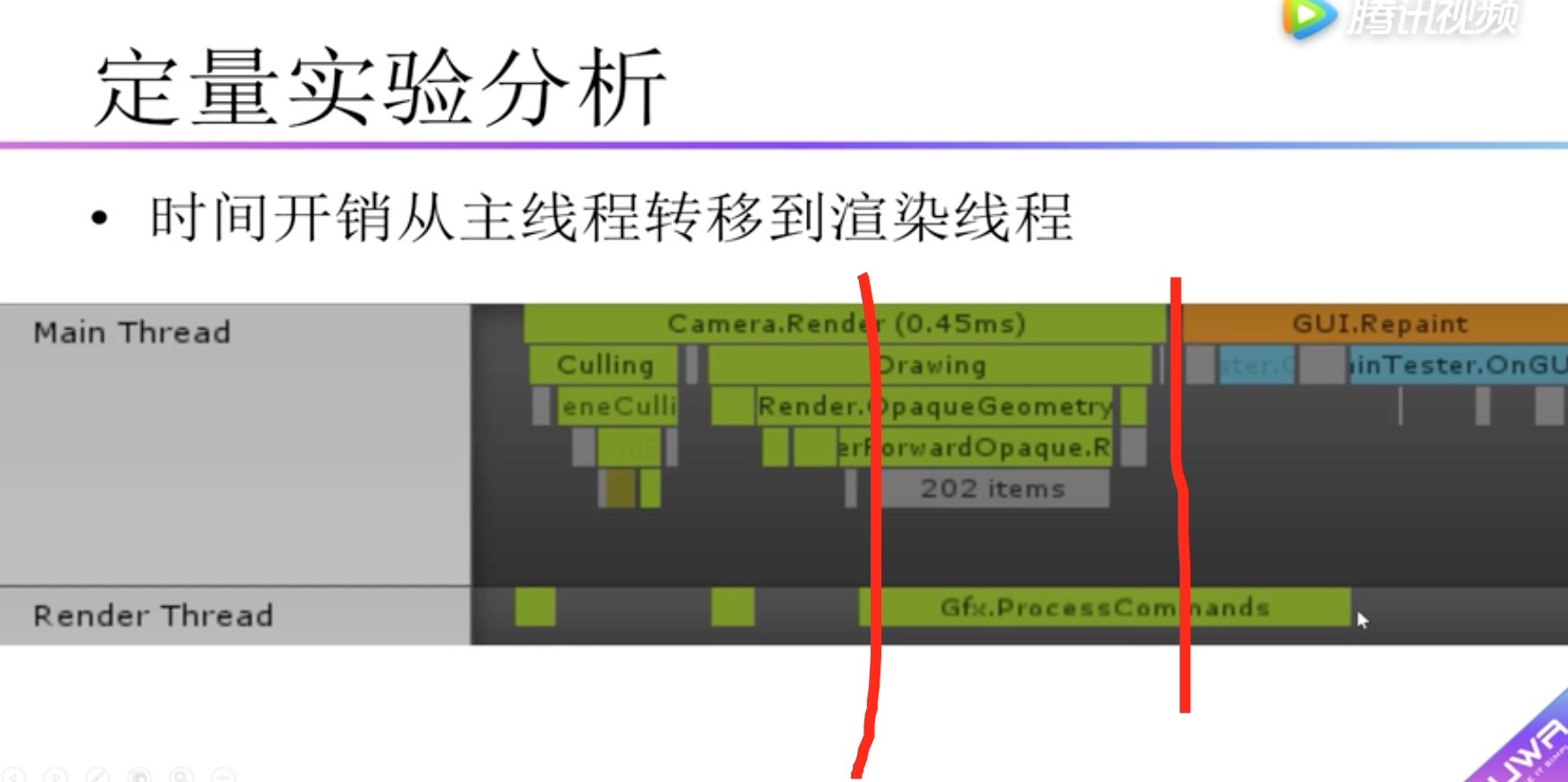
在本次测试中不开启多线程渲染,为什么呢?
因为开启了多线程渲染,主线程中提交DrawCall与图像API的交互操作转移到了渲染线程。使得用Camera.Render衡量不准确。
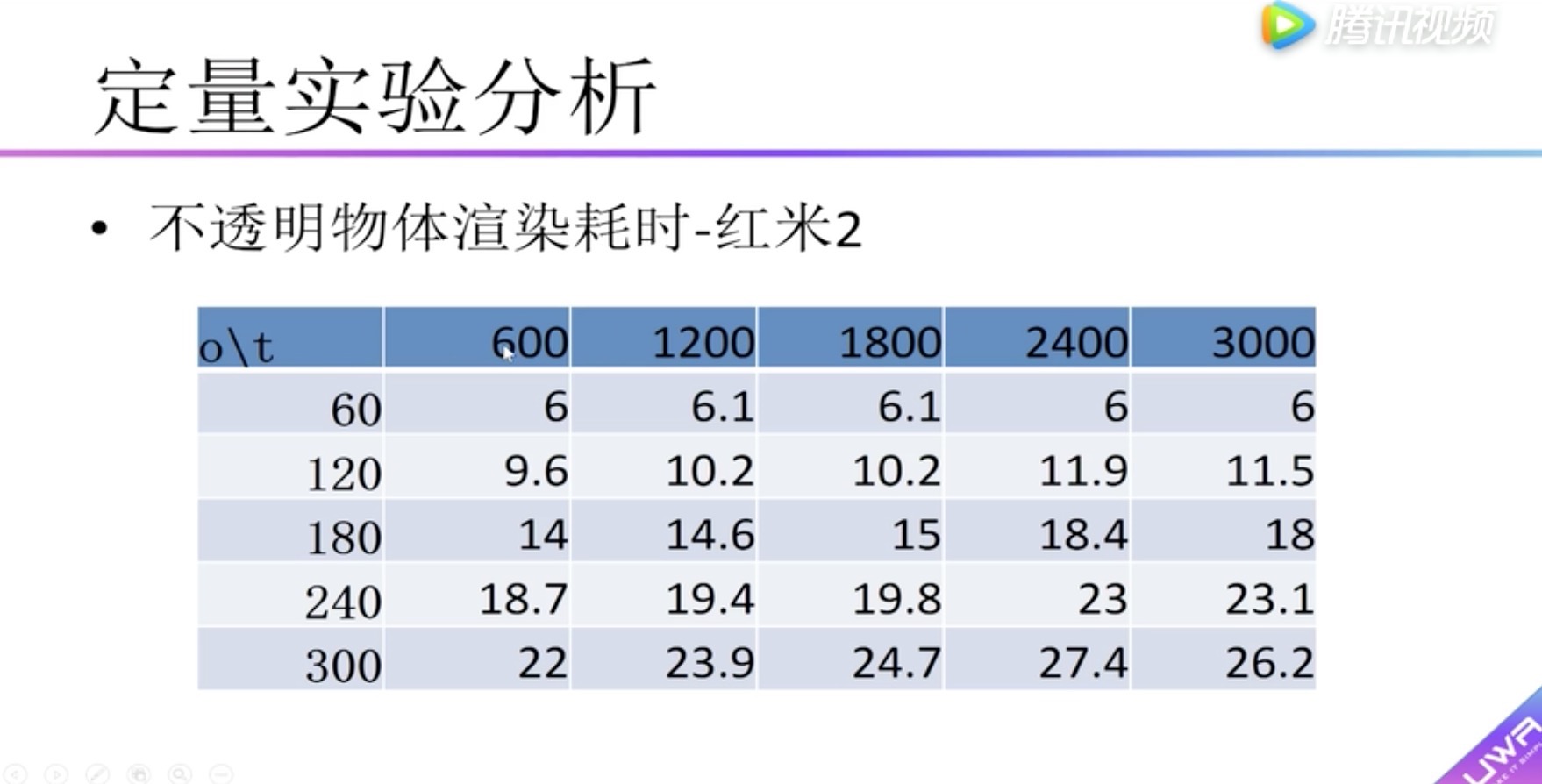
横向表头:面片数
纵向表头:物体数量
boady:渲染耗时,小于5毫秒用红色标识。可以看到在红米2中没有小于5毫秒的情况
可以看到在红米2中没有小于5毫秒的情况,因此在红米2上建议采用面片数量小于600的模型,物体数量小于60个。
定量实验分析 不透明物体渲染性能实验
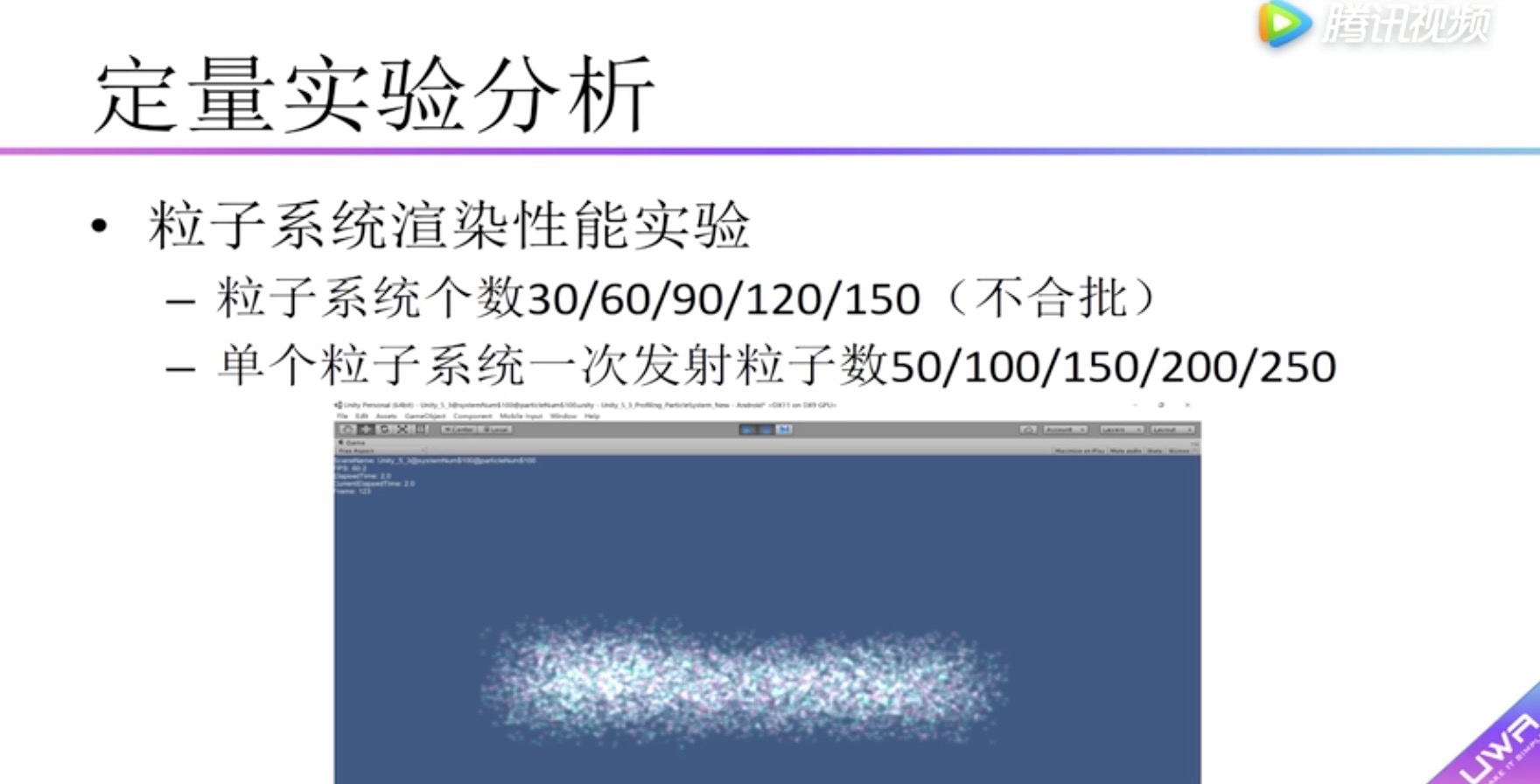
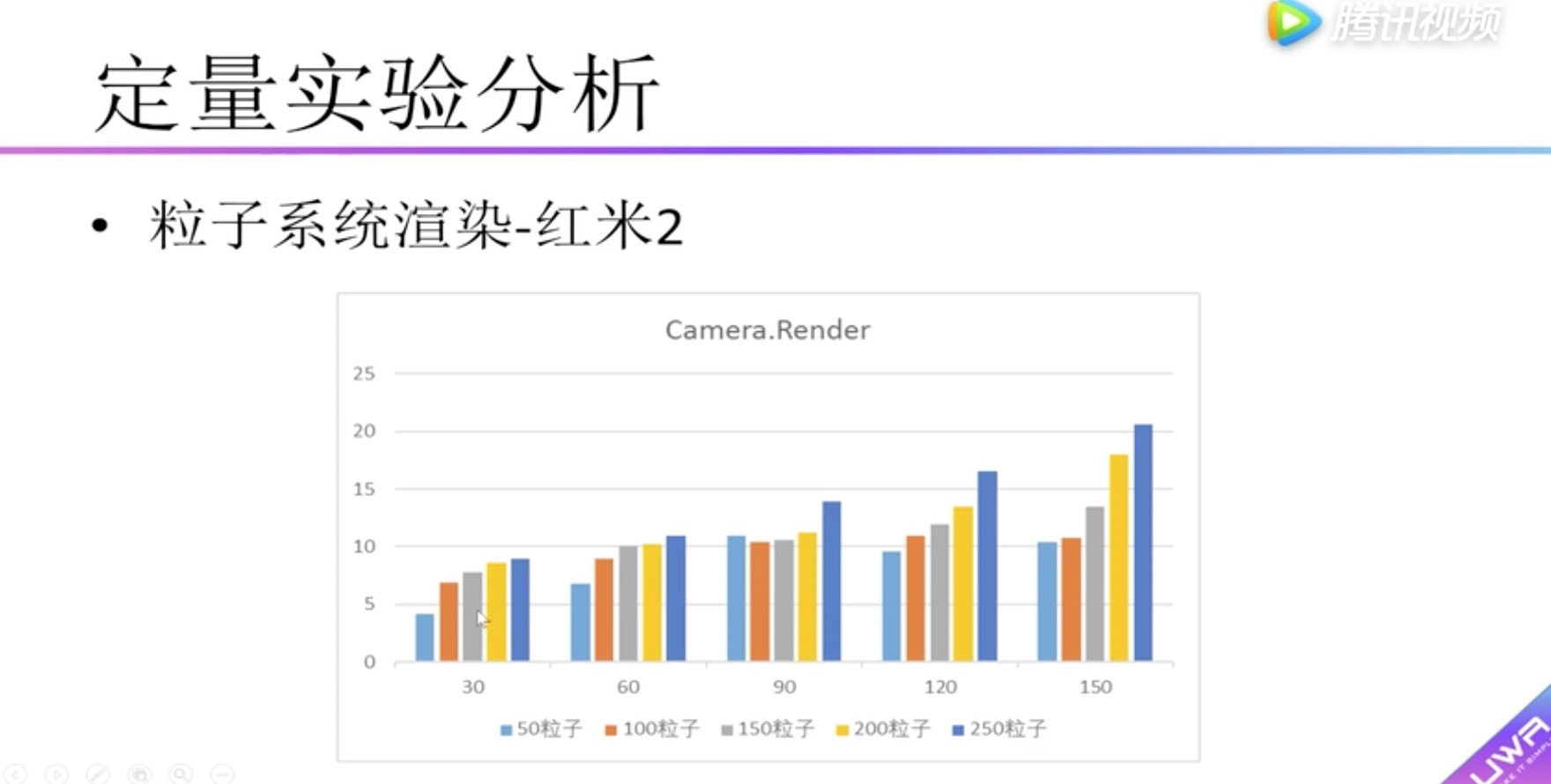
纵向表头:渲染耗时
横向表头:粒子系统数量
柱状图:单个粒子系统的粒子统数量
红米2中可以看到:
粒子系统数量越多,消耗越大。
粒子系统中的粒子数量越多,消耗越大。


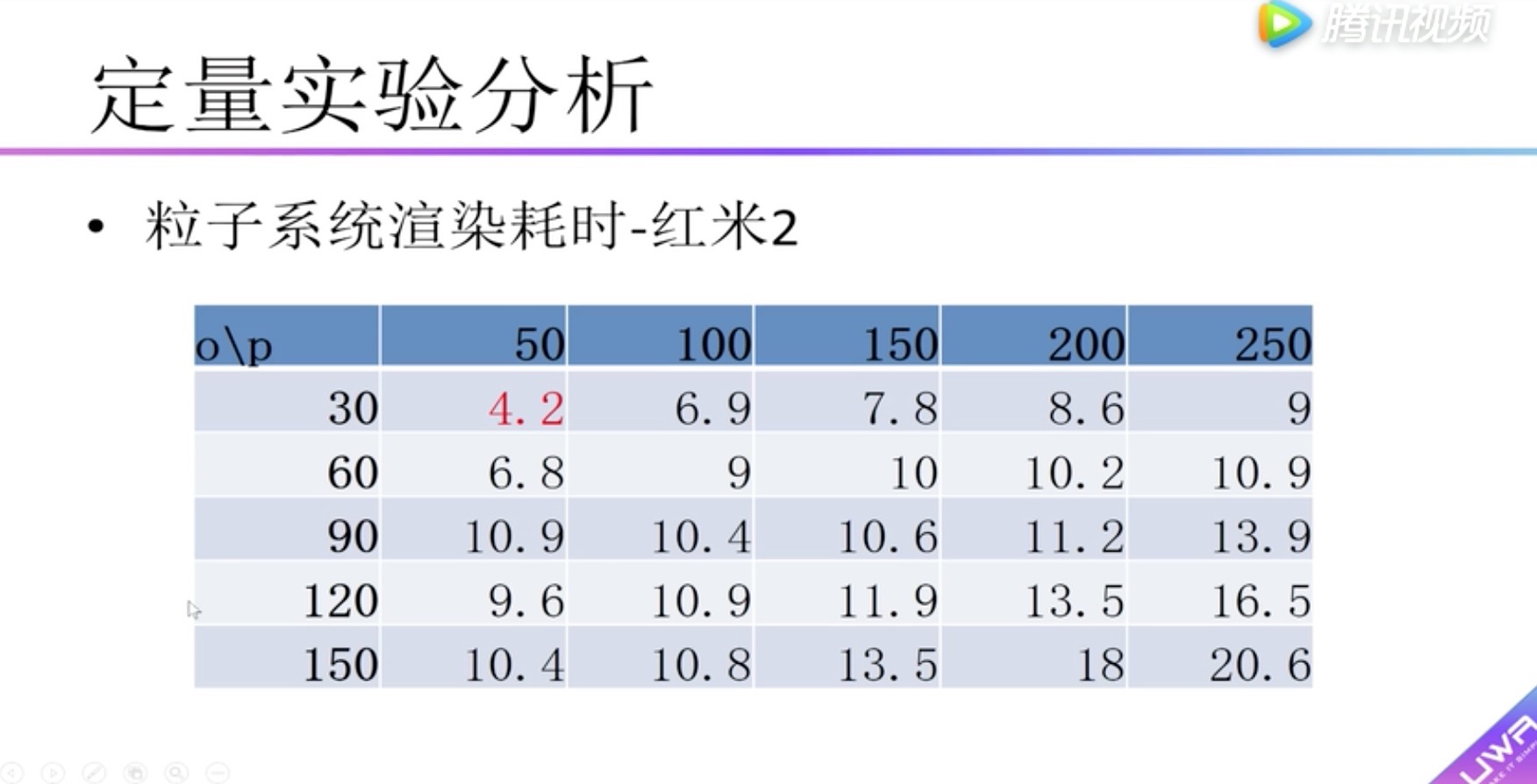
横向表头:单个粒子系统的粒子统数量
纵向表头:粒子系统数量
boady:渲染耗时,小于5毫秒用红色标识。可以看到在红米2中小于5毫秒的情况设置是30个粒子系统,单个粒子系统的粒子个数40
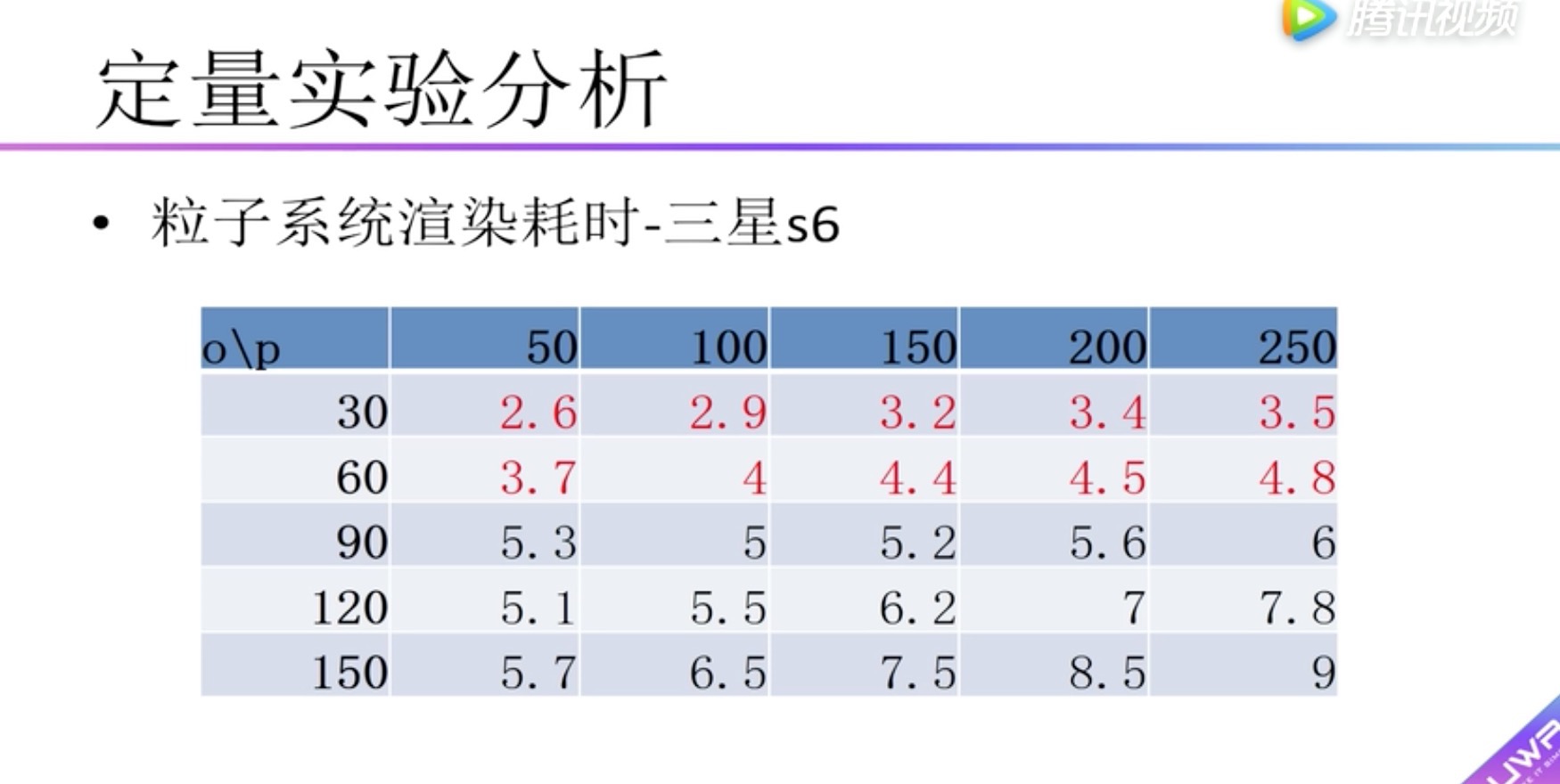
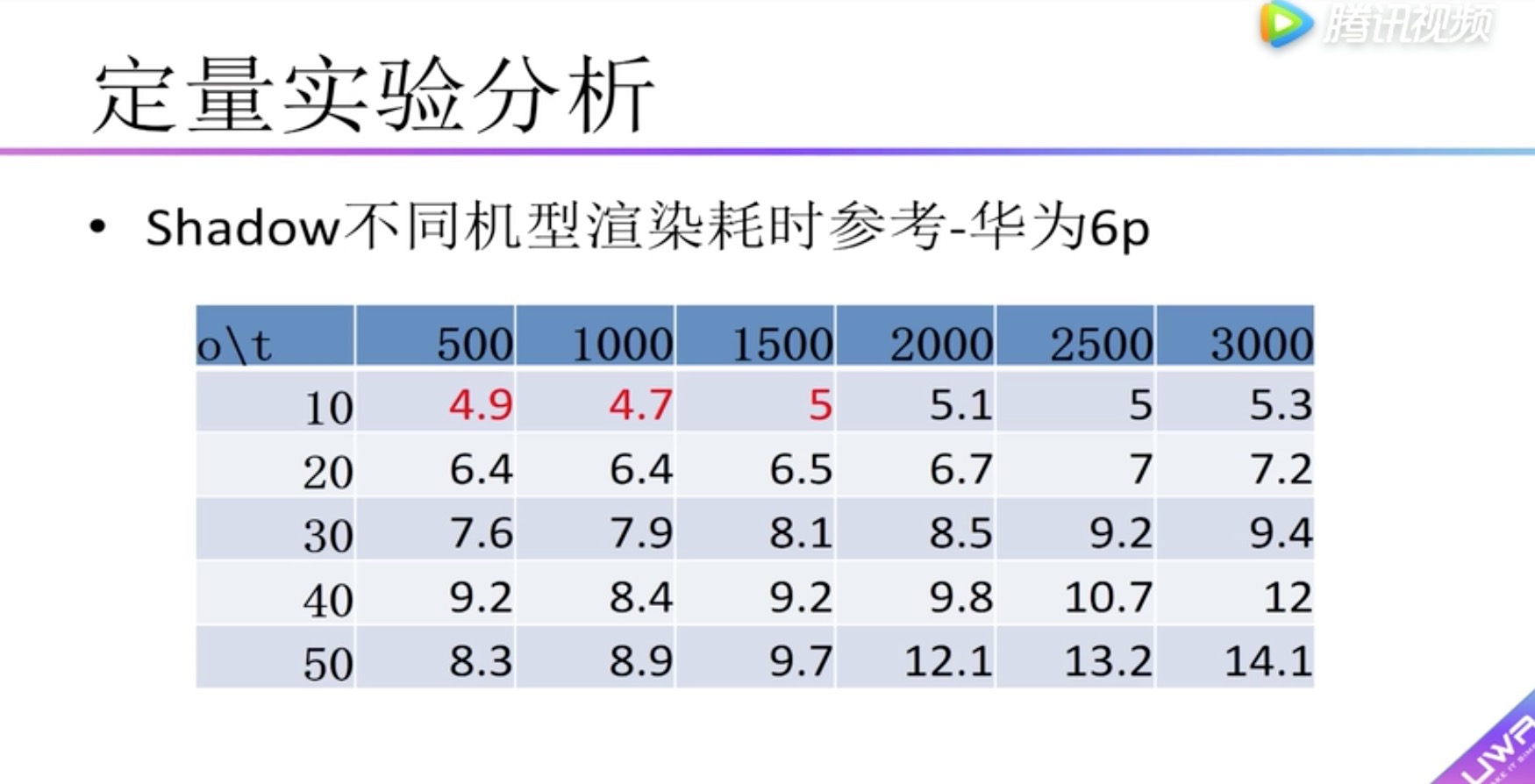
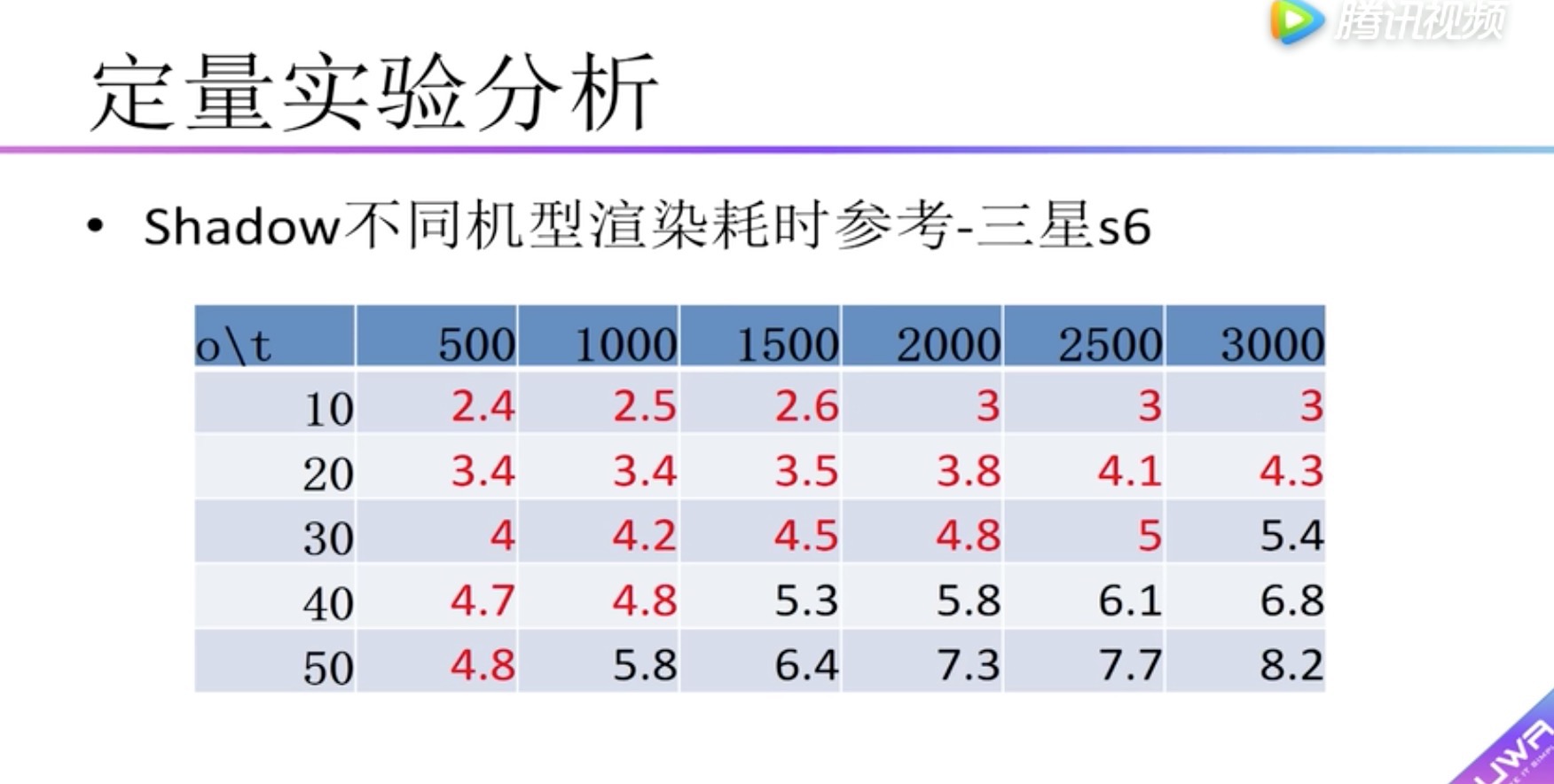
定量实验分析 Shadow

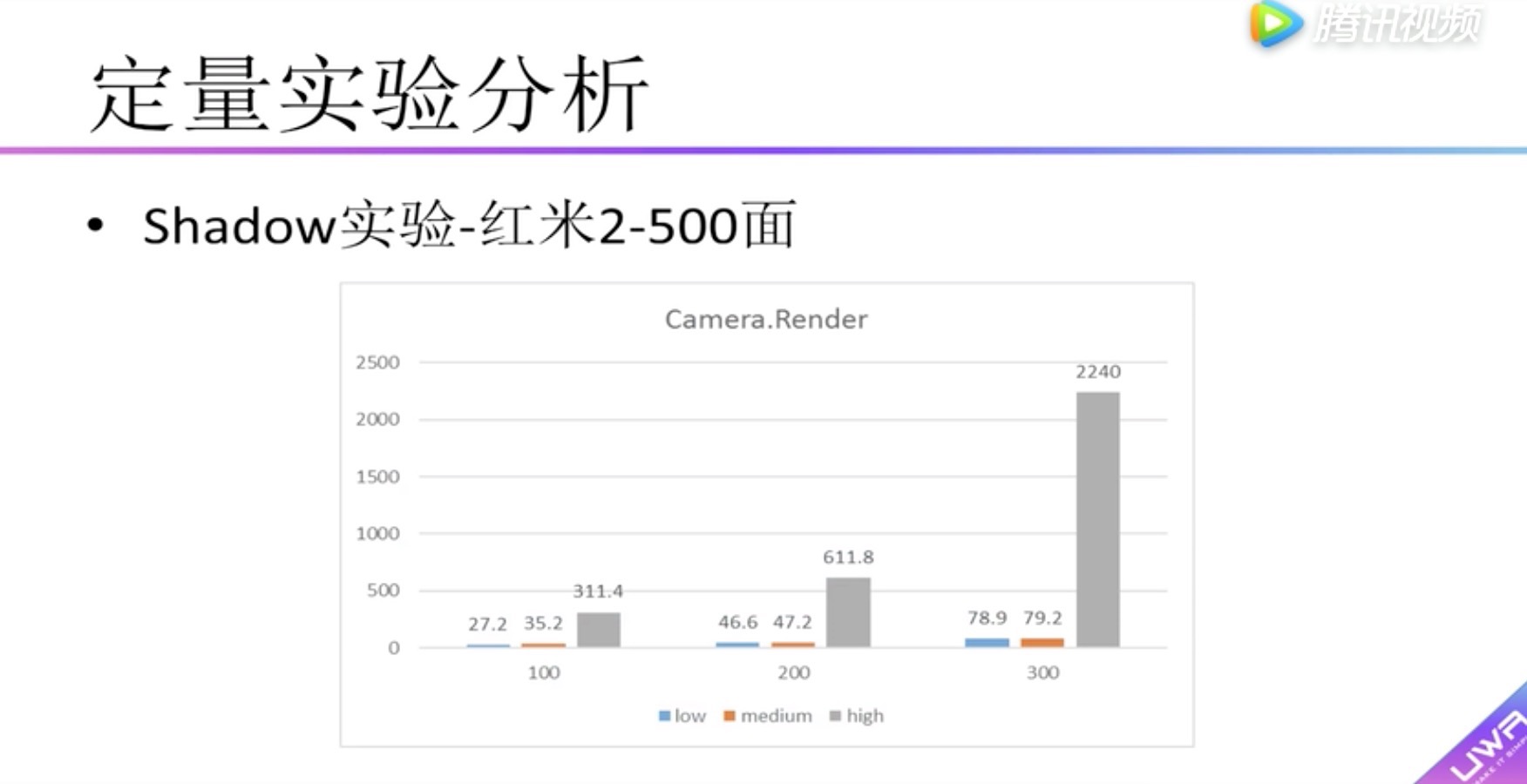
纵向表头:Camera.Render渲染总耗时 (毫秒)
横向表头:物体的个数
柱状图:表示低、中、高三种分辨率的ShadowMap
红米2测试,面片数选择500个
ShadowMap分辨率 (低、中)和(高)有很大的差距
ShadowMap分辨率 (低)和(中)差距不是很大

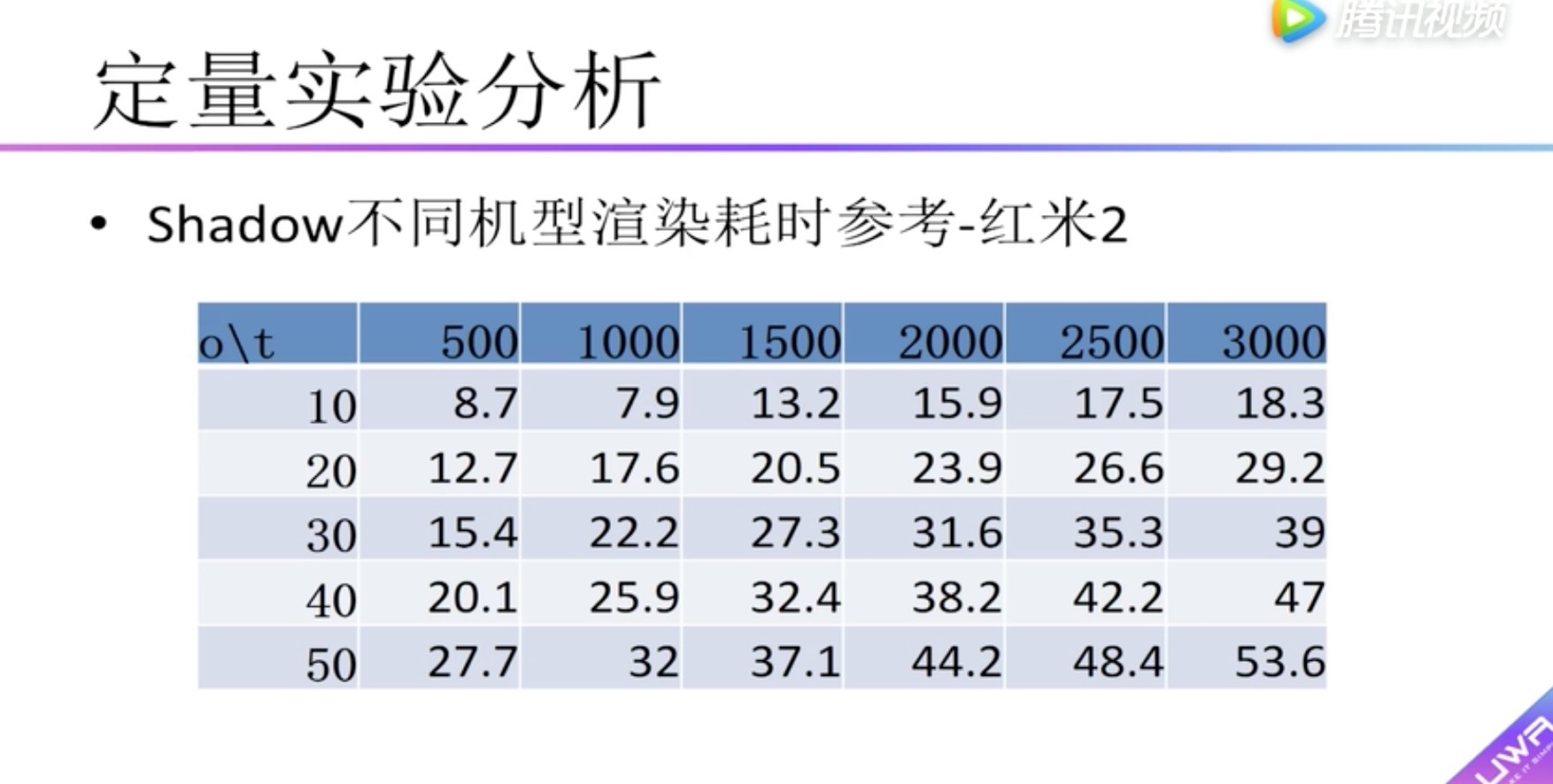
横向表头:单个物体的面片数量
纵向表头:物体数量
boady:渲染耗时,小于5毫秒用红色标识。可以看到在红米2中没有小于5毫秒的情况,因此在红米2上建议不要开启实时阴影。
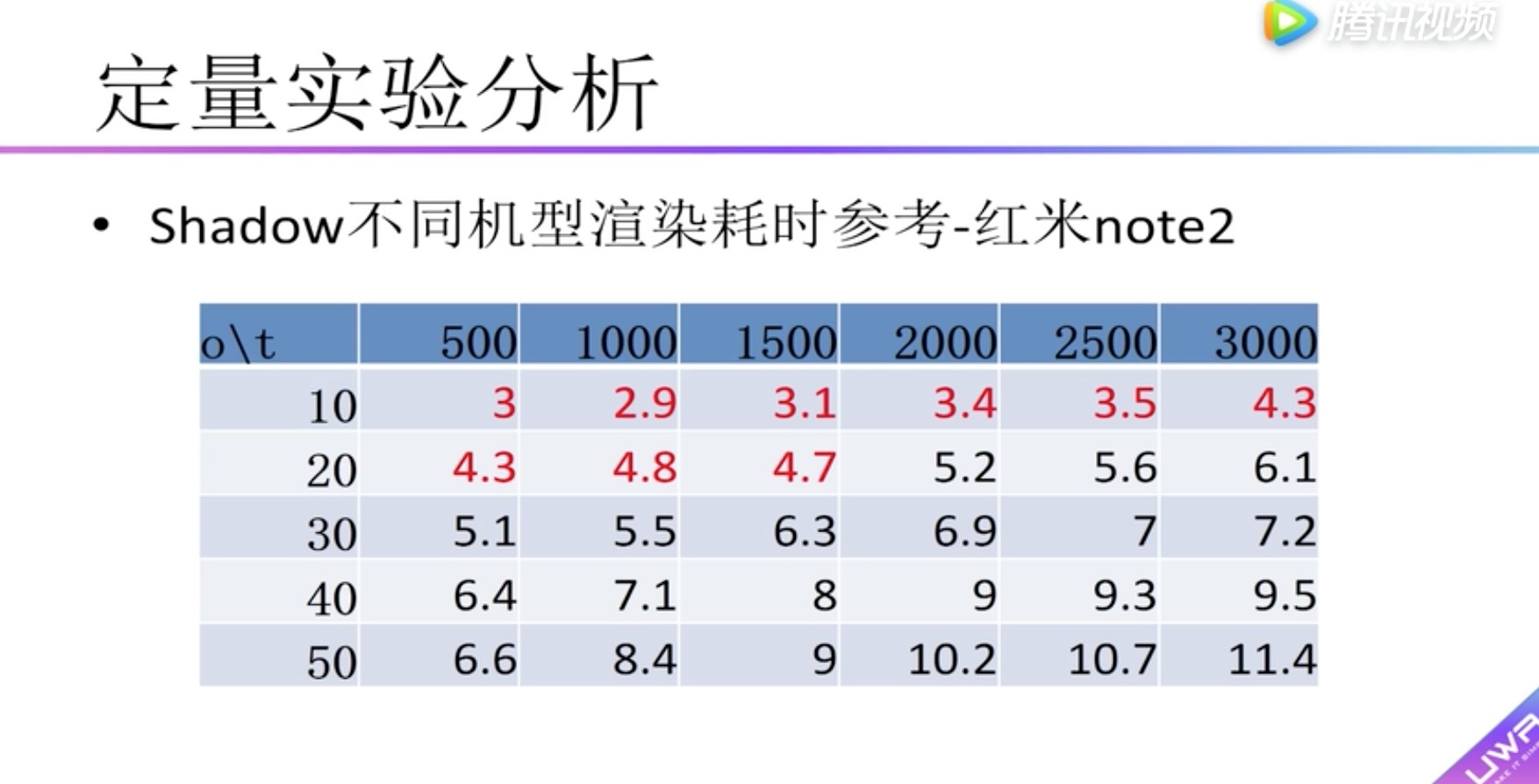
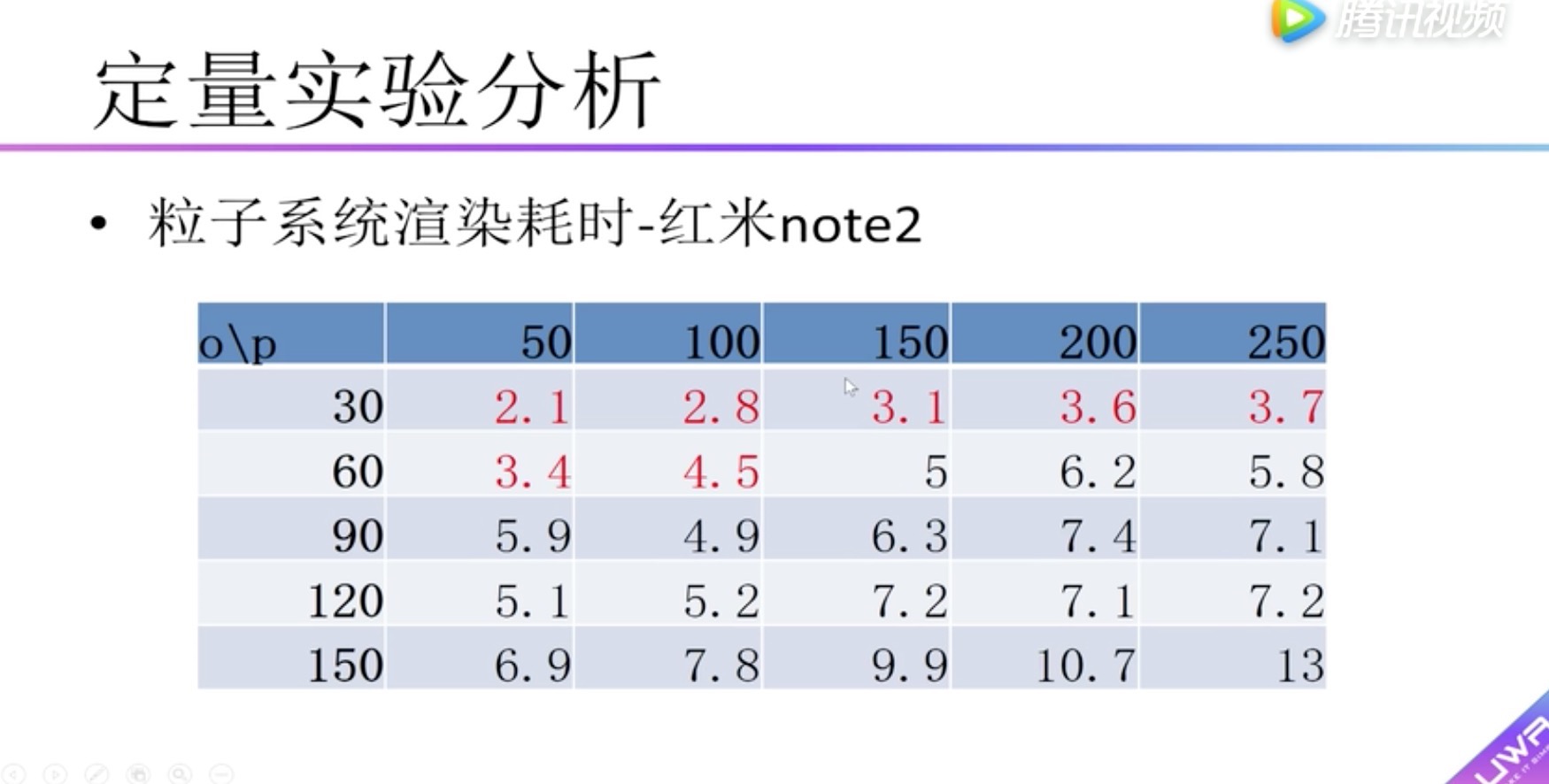
红米note2中最大支持面片数为1500个的物体20个。
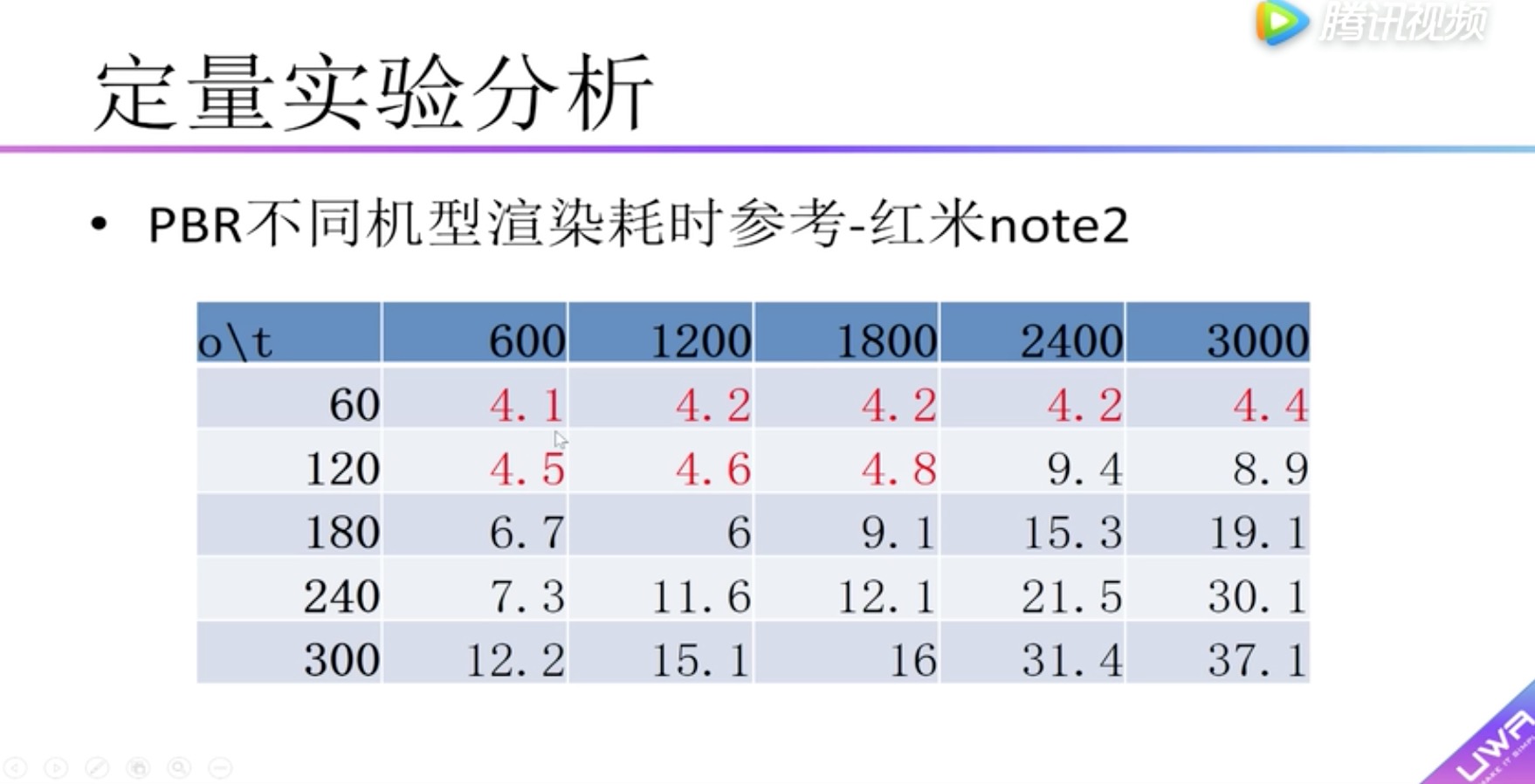
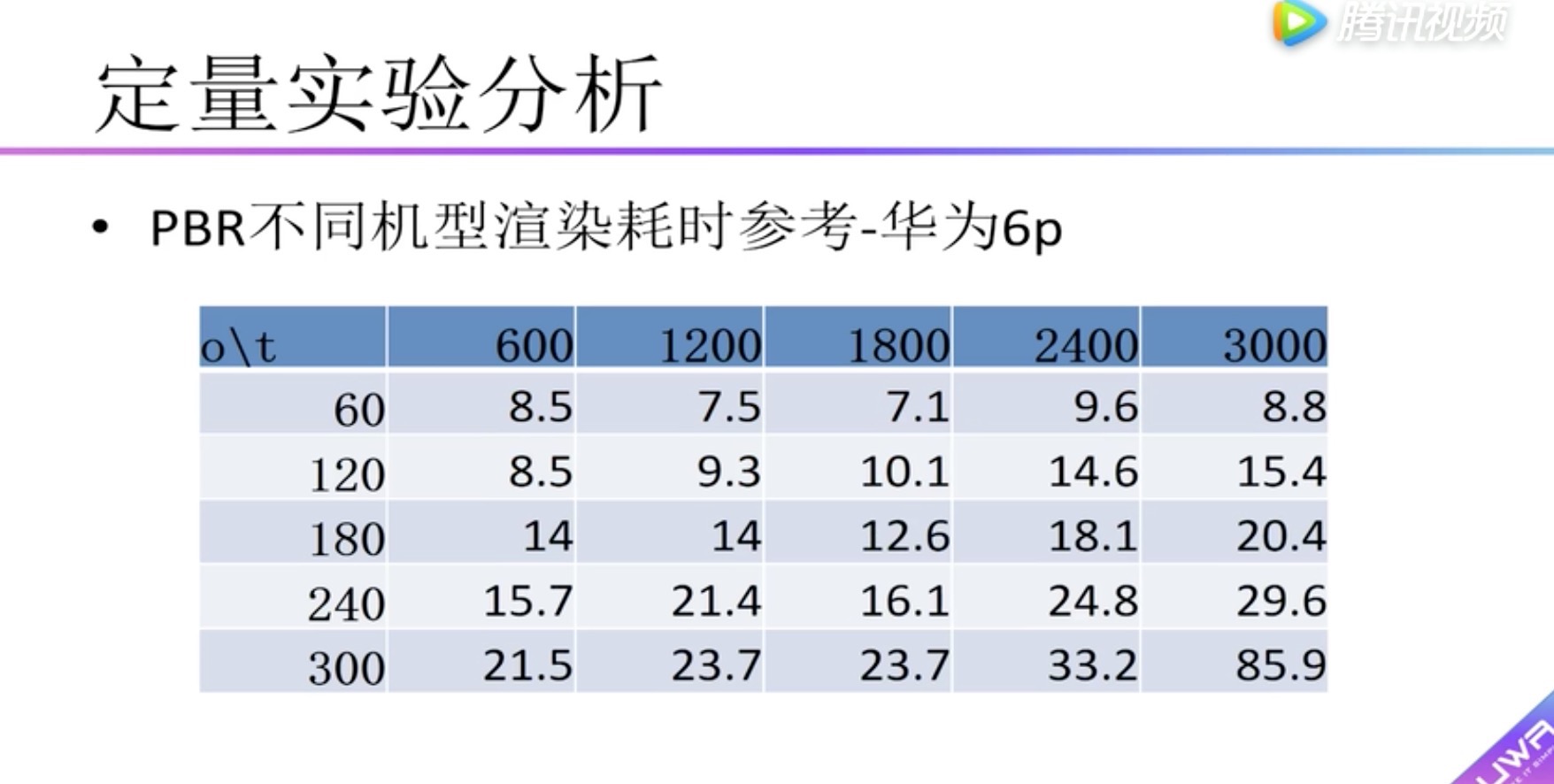
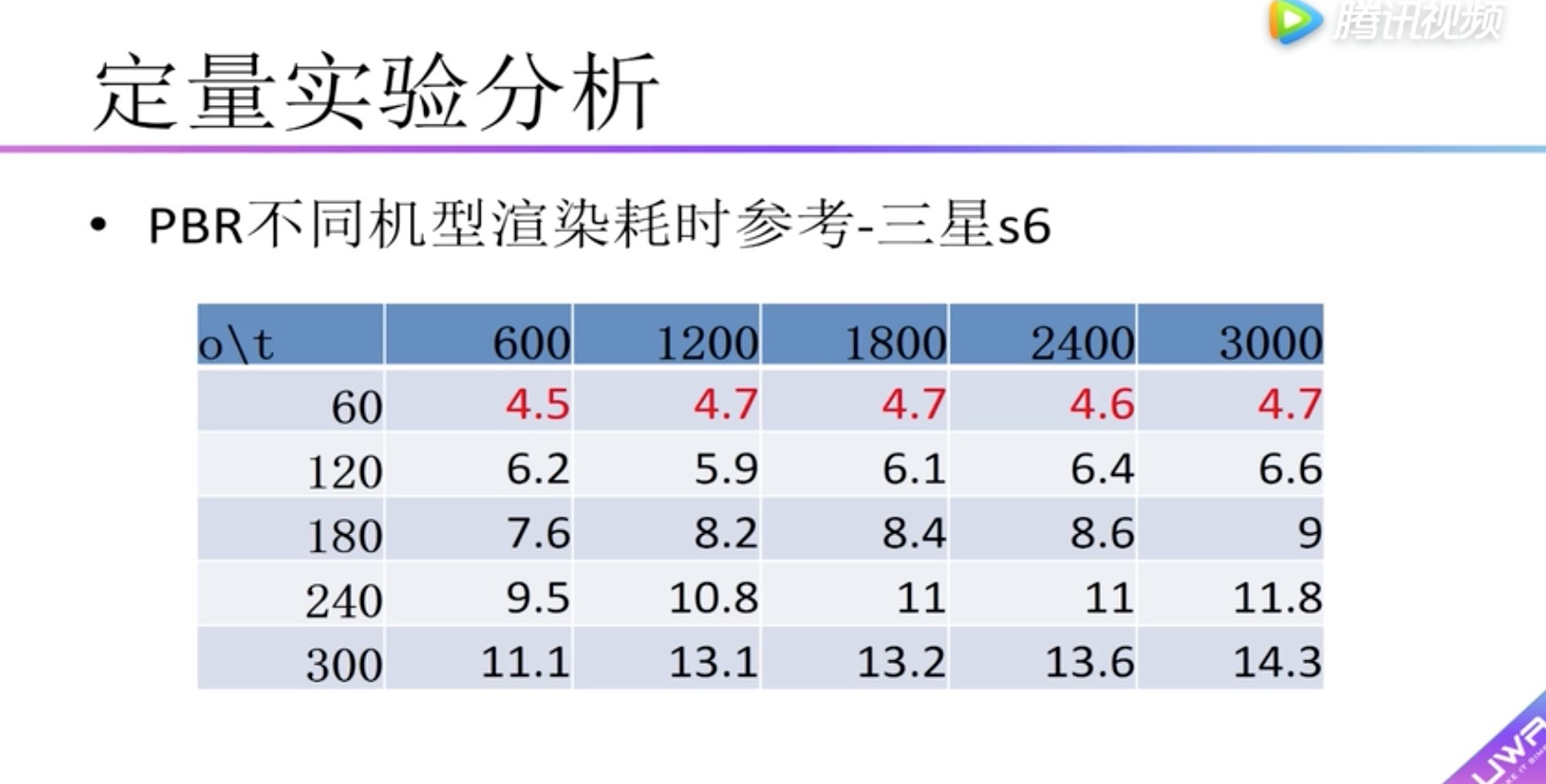
定量实验分析 PBR与简单光照对比

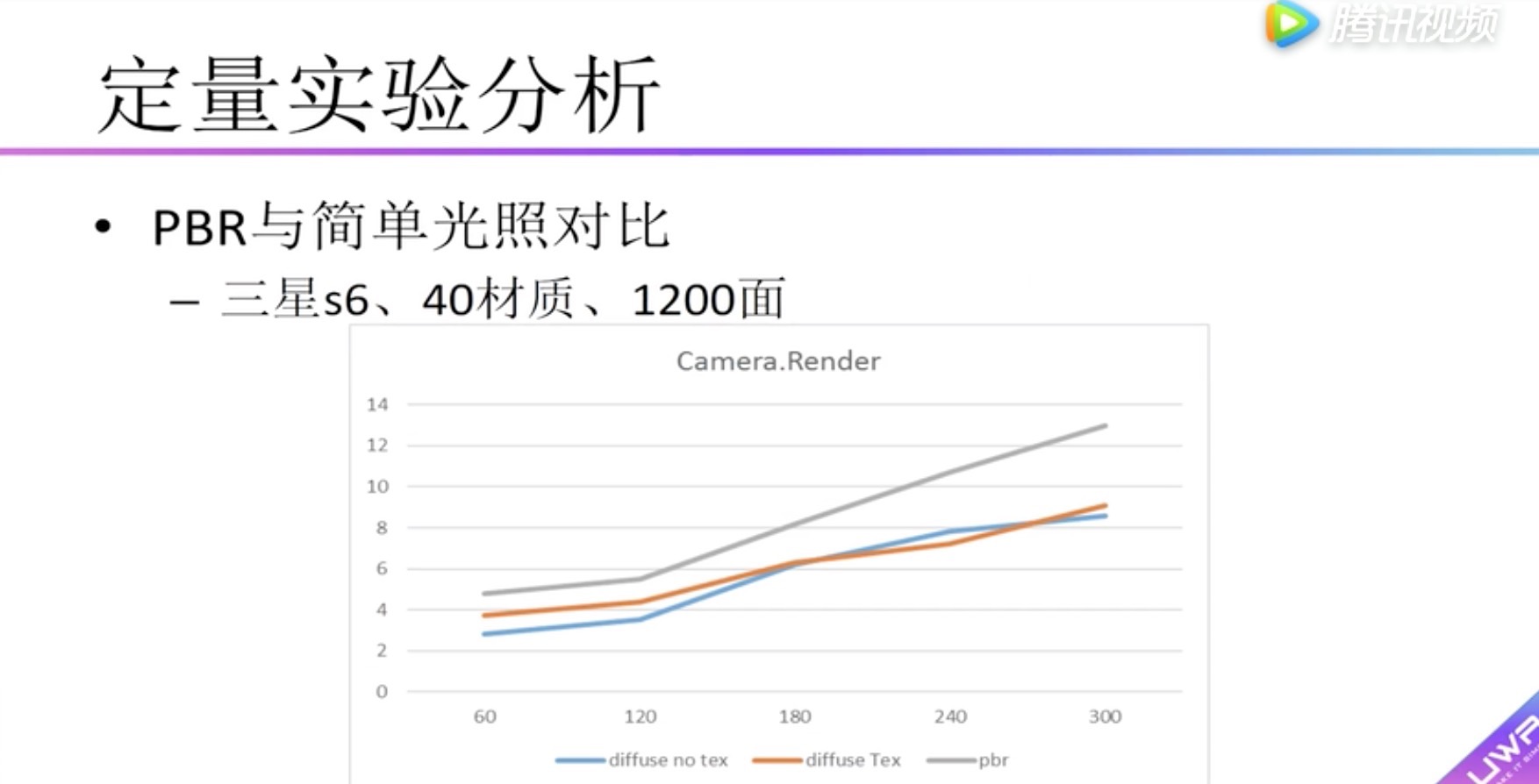
纵向表头:Camera.Render渲染总耗时 (毫秒)
横向表头:物体的个数
蓝色:diffuse材质,没有贴图
红色:diffuse材质,有贴图
灰色:pdr材质
发现:pdr材质比diffuse耗时高一些,没有高很多,60个物体高2ms,300个物体高4ms。
为什么呢?
因为pdr的主要工作在gpu

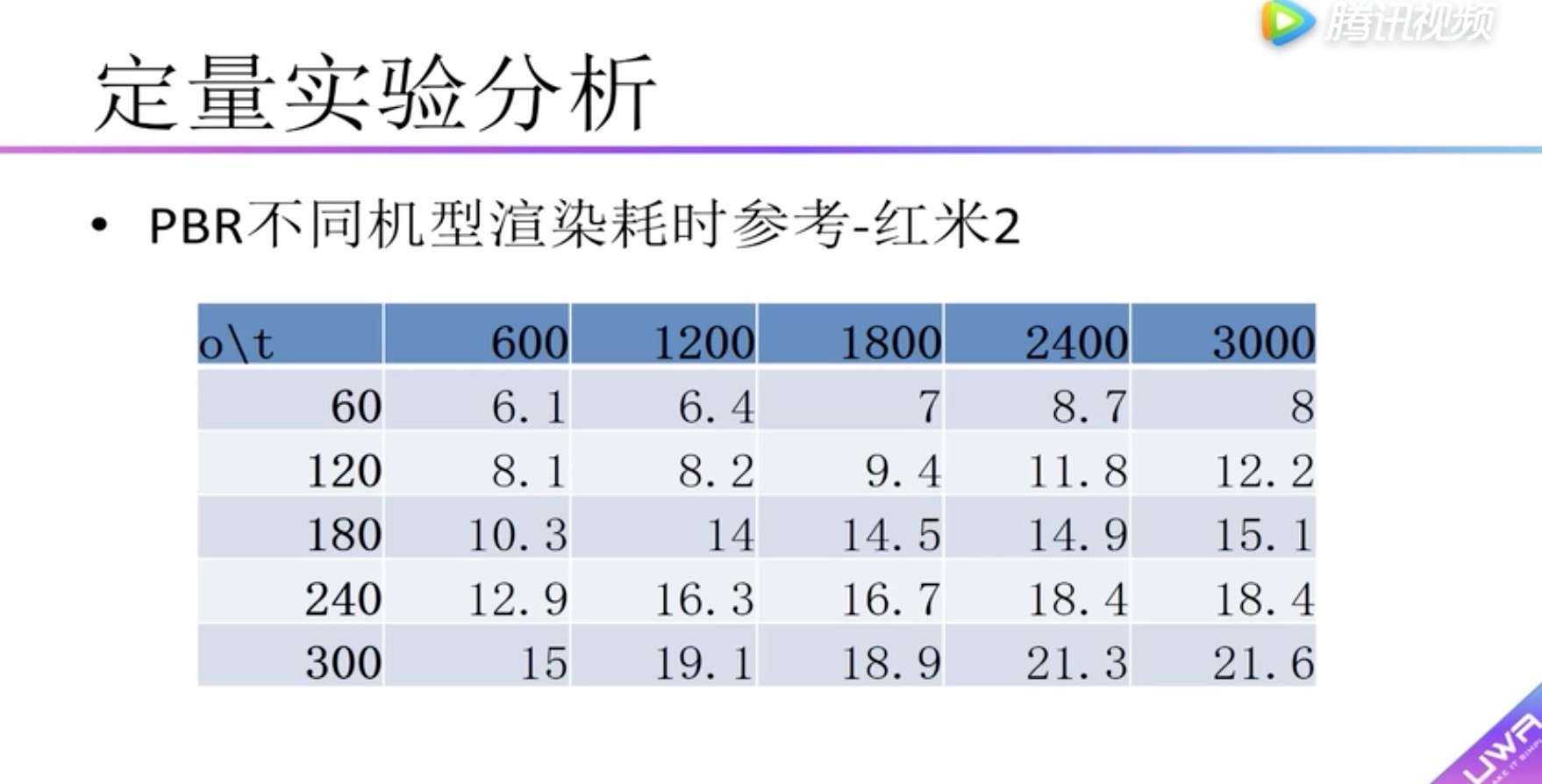
横向表头:单个物体的面片数量
纵向表头:物体数量
boady:渲染耗时,小于5毫秒用红色标识。可以看到在红米2中没有小于5毫秒的情况,因此在红米2上建议不要使用pdr。
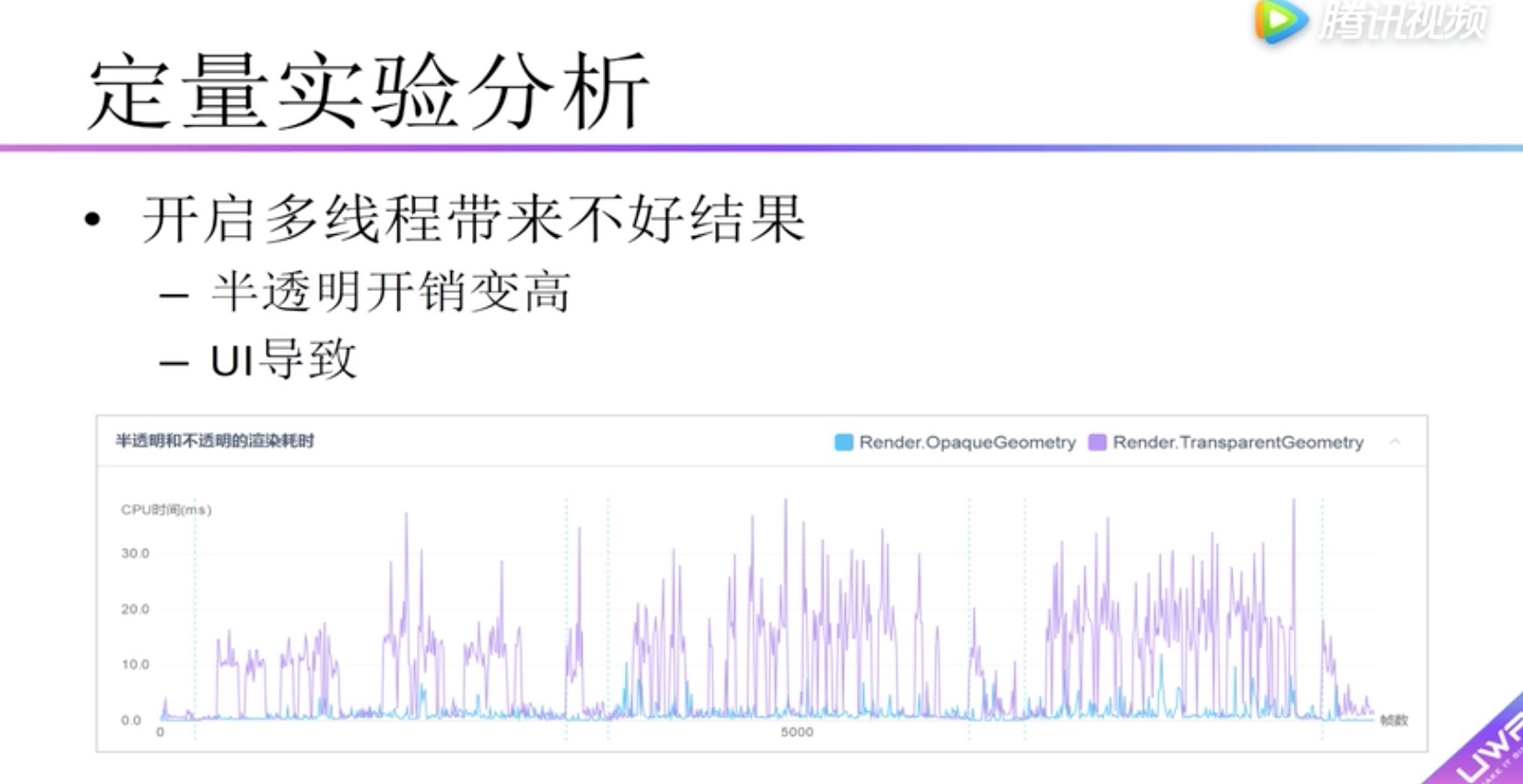
定量实验分析 多线程性能提升实验





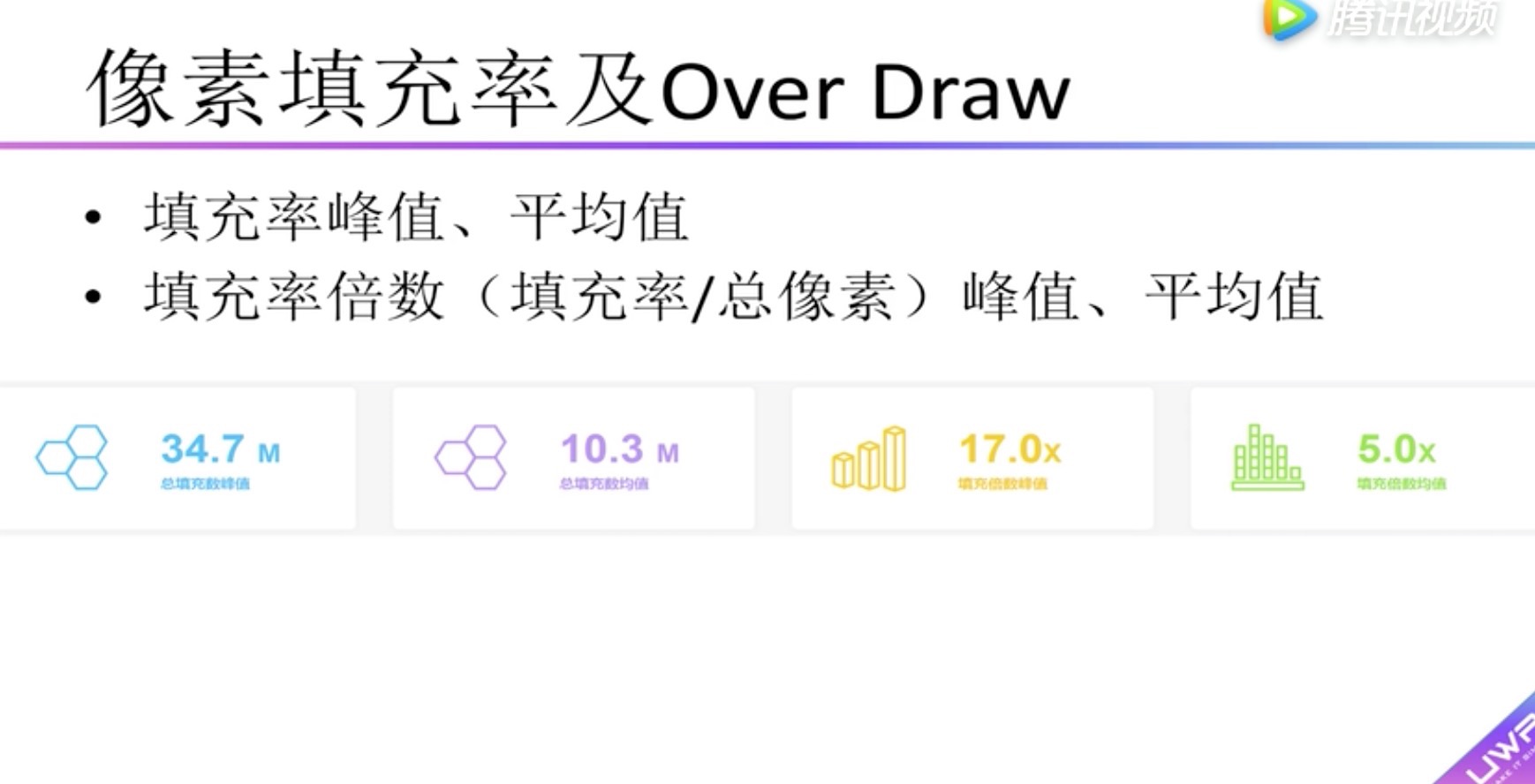
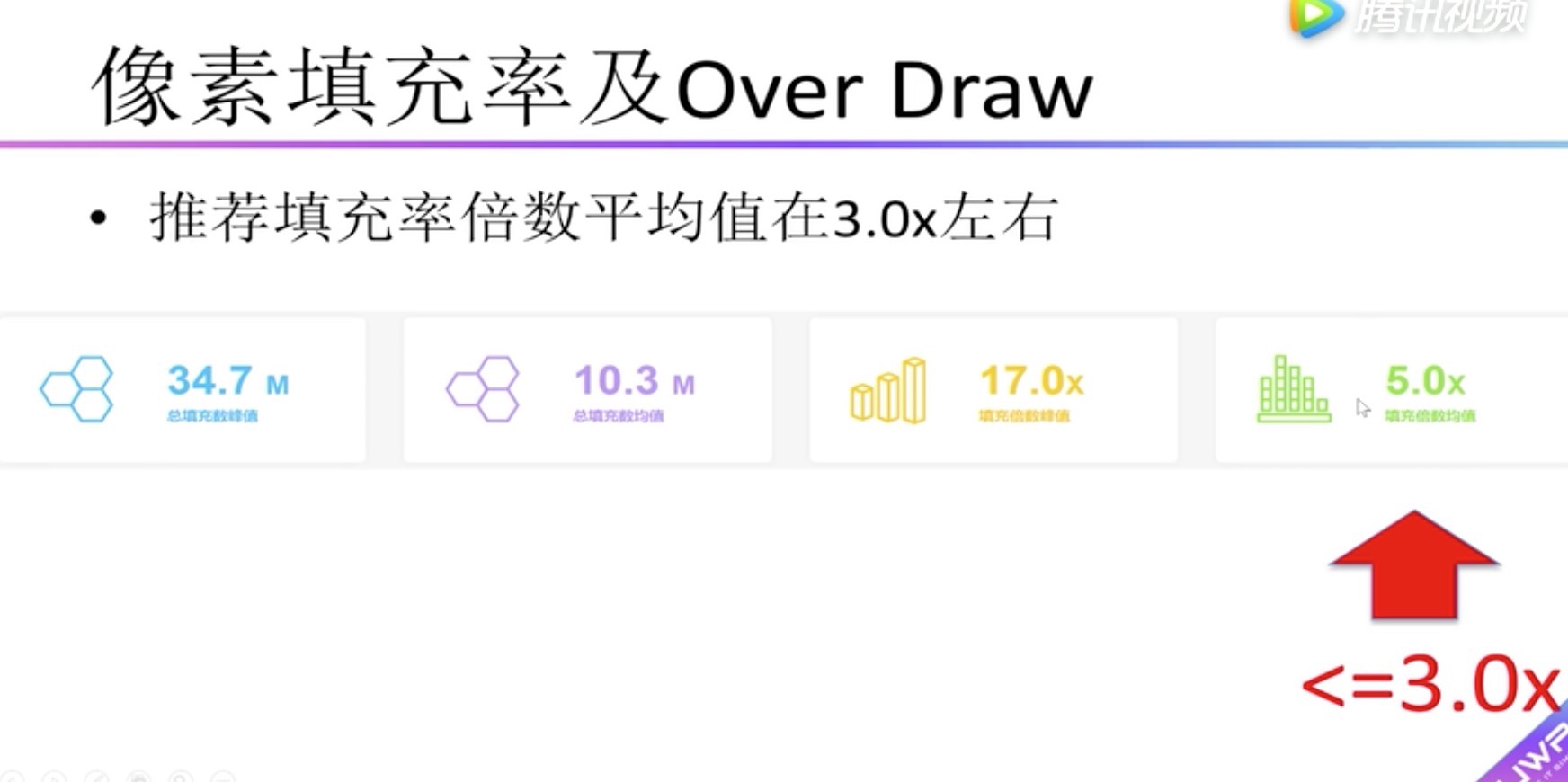
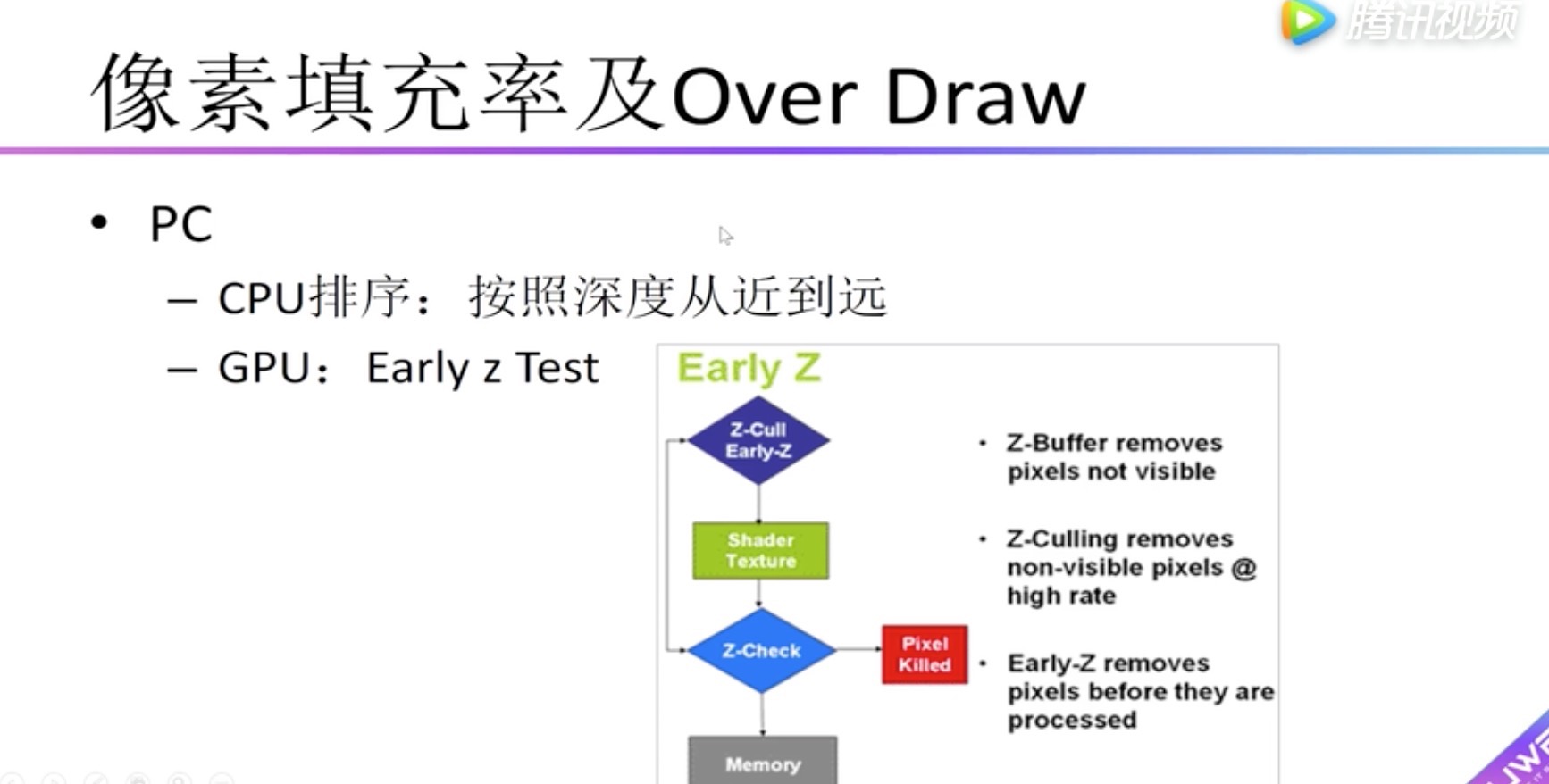
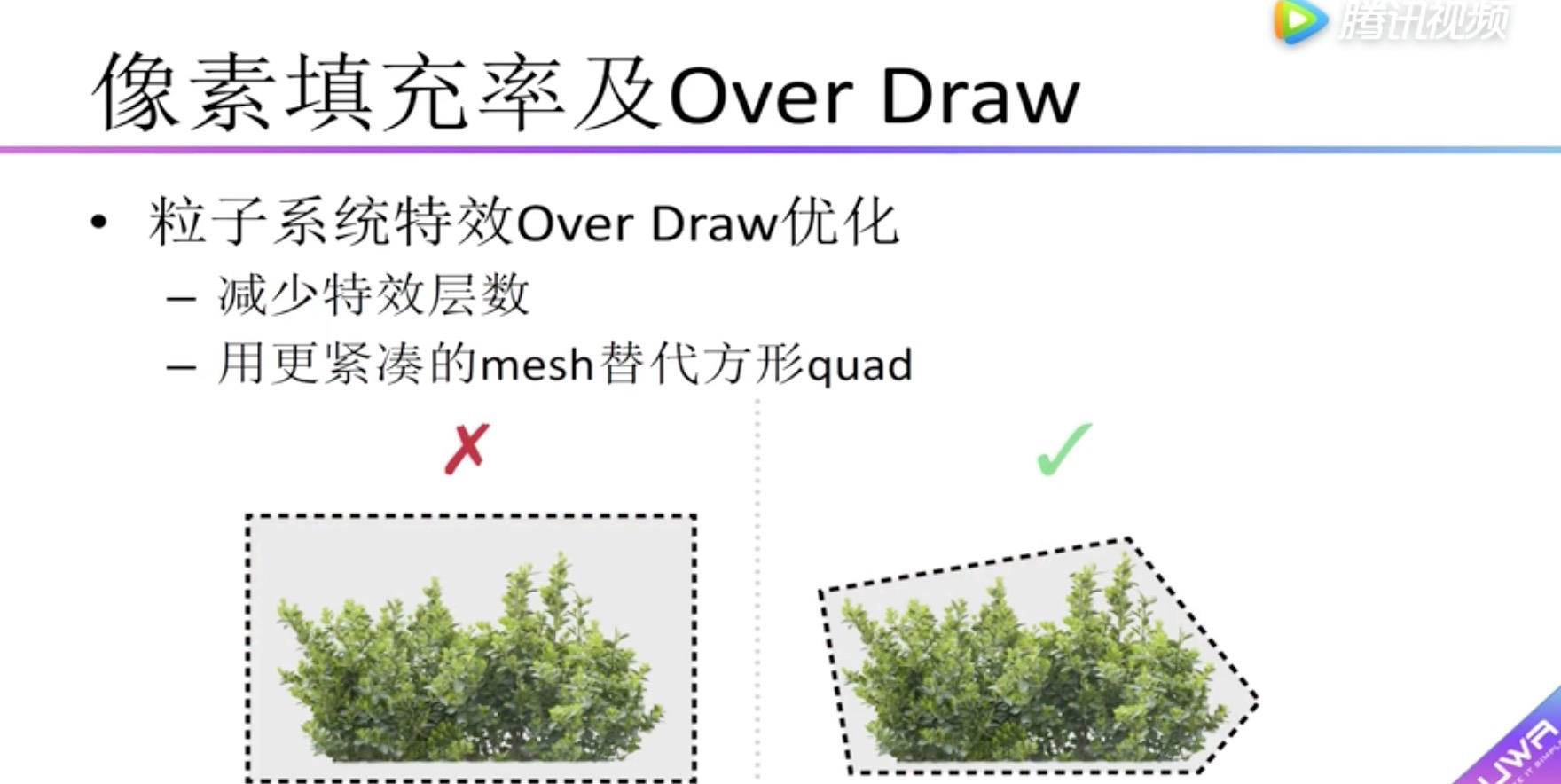
GPU 像素填充率及Over Draw







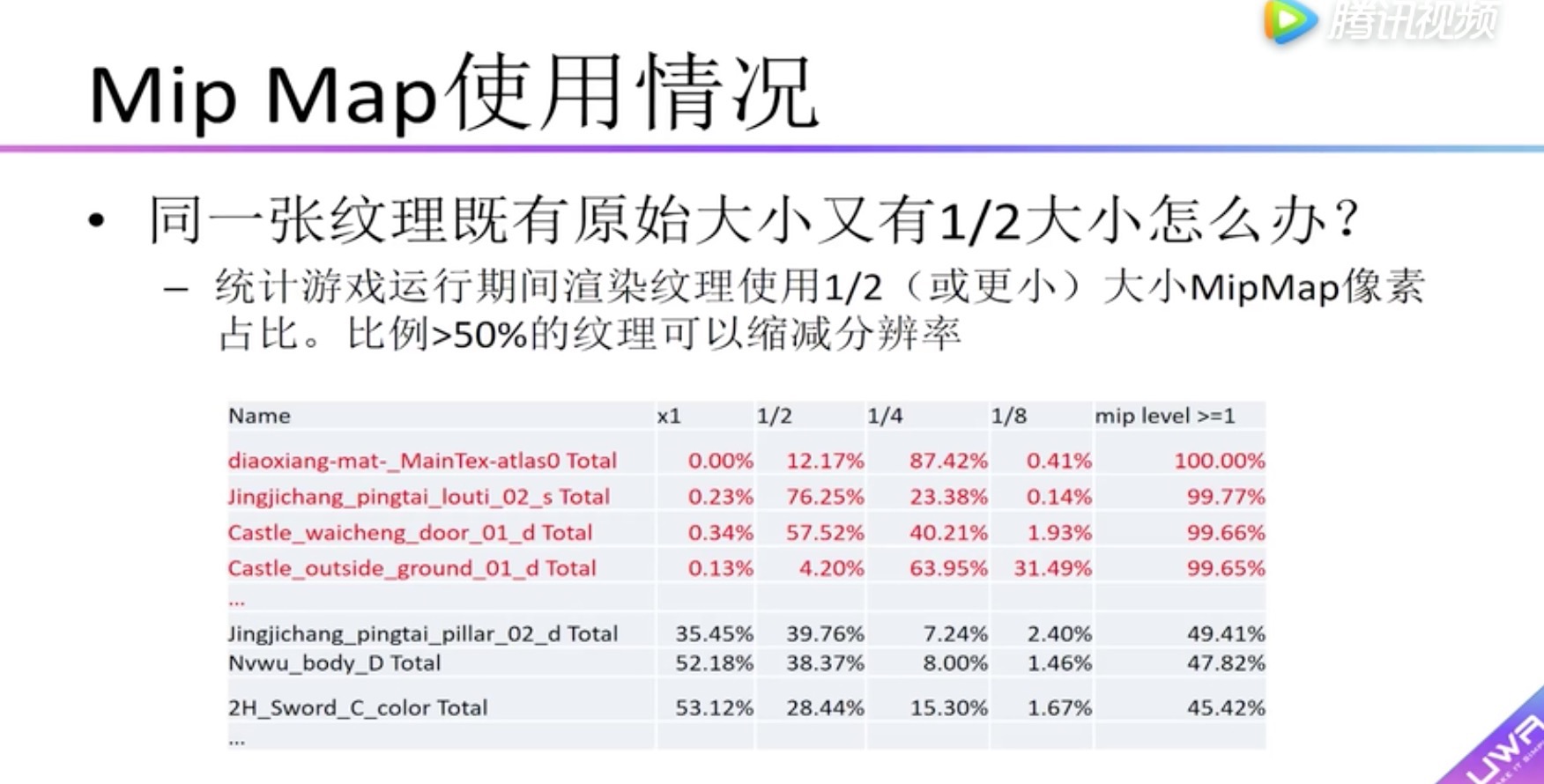
GPU MipMap

GPU Culling
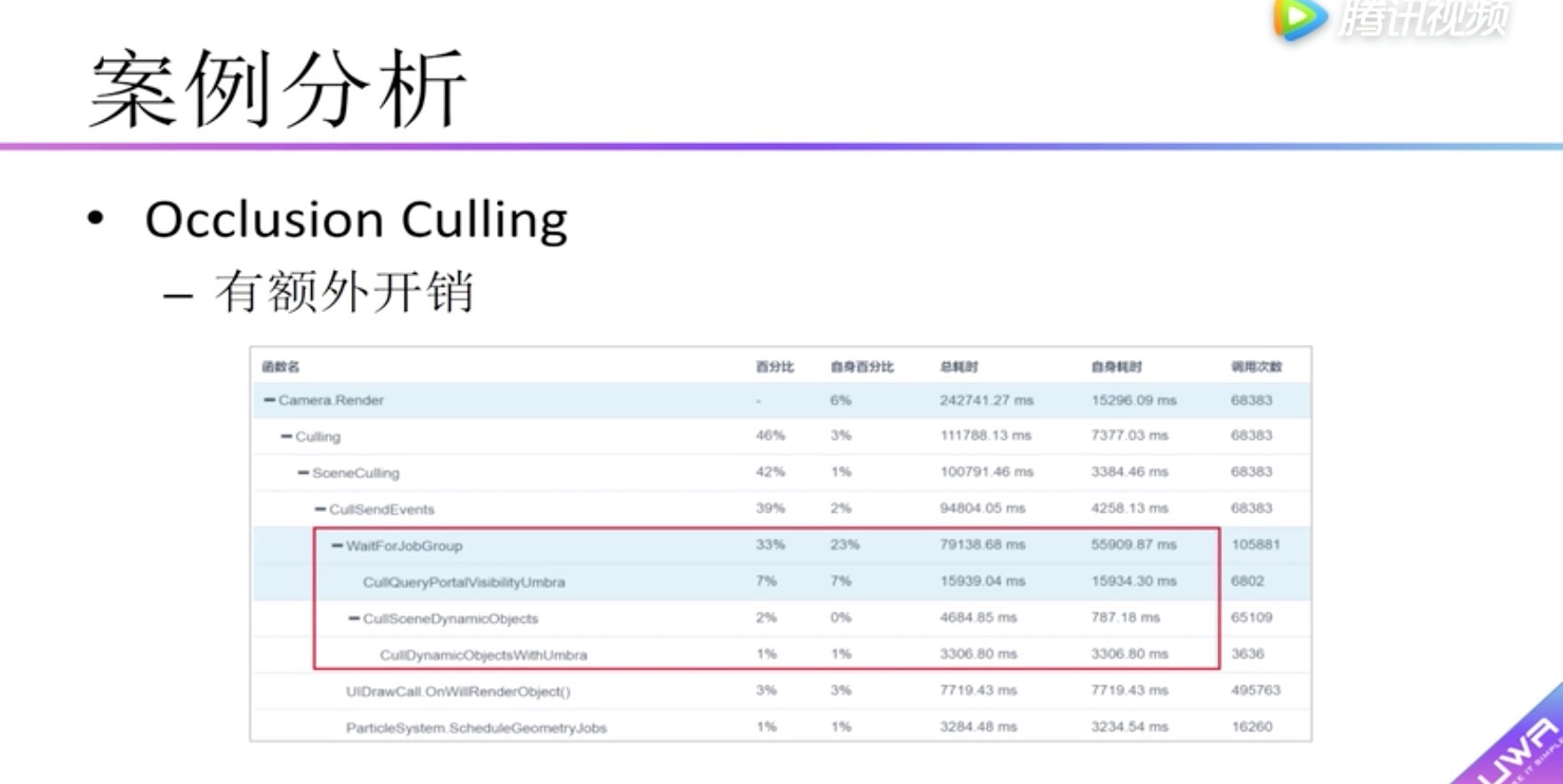
Occlusion Culling, Unity Camrea的功能。对场景中静态的物体预计算,然后在动态渲染的时候查预算的数据分析静态物体是否被其他静态物体遮挡。如果遮挡了,就把该物体刨除掉从而降低Draw Call。但是查询CullQueryPortalVisibityUmbra是有一定开销的
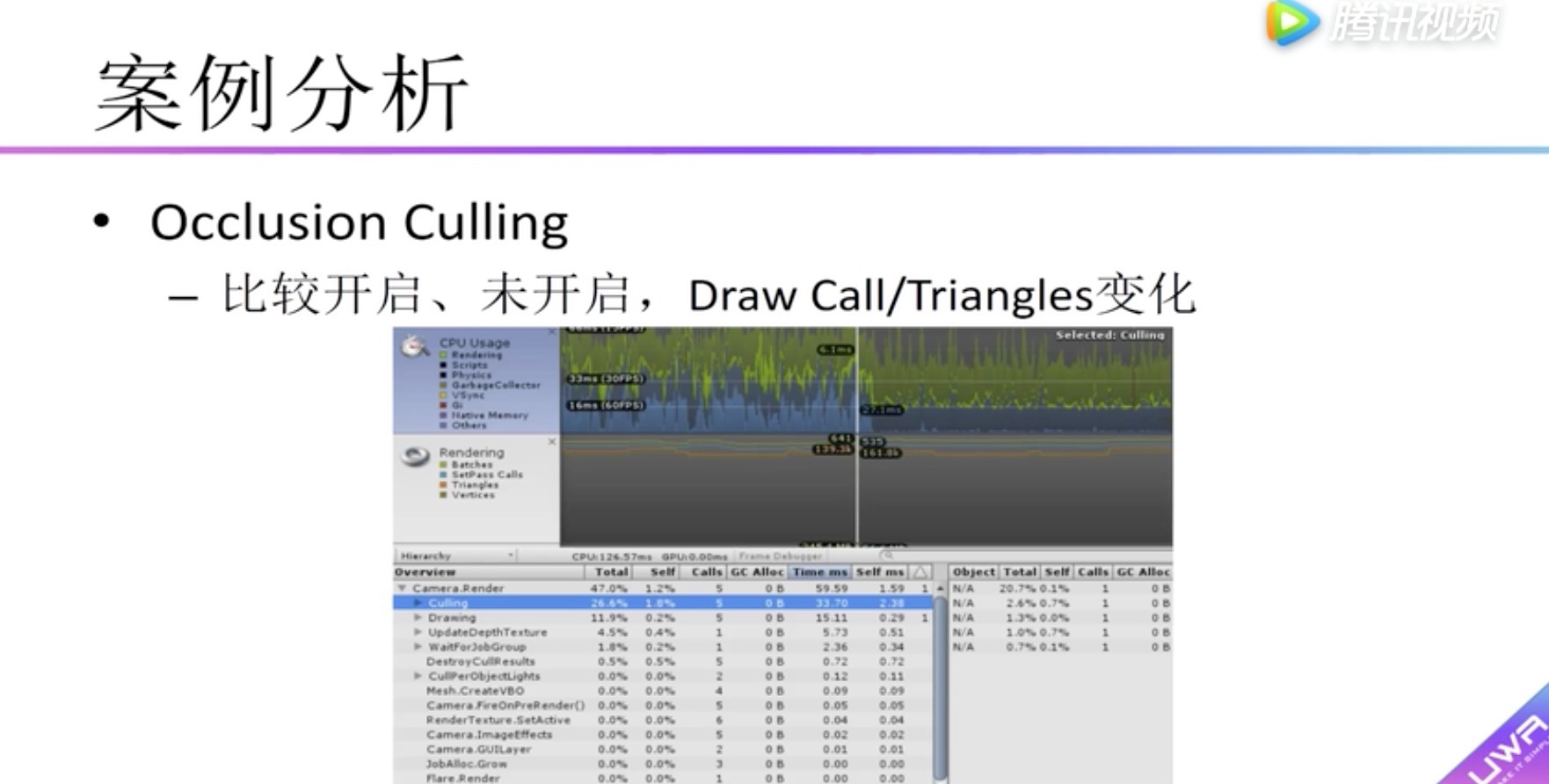
有些特殊情况,我们对比开启和关闭Occlusion Culling发现:
Occlusion Culling 开启有一定的开销
Draw Call并没有什么变化
因此在这种情况下,可以不开启

减少Draw Call的几种方法
Static Batching:对于静态物体
Dynamic Batching:对于动态物体
GPU Instancing:Unity5.4以后的版本,支持GPU3.1,对CPU没有开销,在GUP有一点点Shader开销。
Static Batching和Dynamic Batching对CUP和内存都有而外的开销,他们对对顶点重新计算